Wiele statystyk gospodarczych wywołuje poruszenie na rynkach, gdy są publikowane po raz pierwszy, a później ponowne – gdy są korygowane. Powodem poruszenia jest to, że dane te często znacznie różnią się od siebie. Powodem jest duży margines niepewności publikowanych wyników. Agencje państwowe pomogłyby społeczeństwom i decydentom politycznym, gdyby jasno to mówiły.
(infografika Dariusz Gąszczyk)
Czytając podawane wyniki warto mieć świadomość co do sposobów pomiaru przejściowej statystycznej niepewności w szacunkach zawartych w oficjalnych statystykach sporządzonych na podstawie niepełnych danych, a także trwałej statystycznej niepewności wynikającej z tego, że wiele osób nie odpowiada na pytania skierowane do nich w ramach badań. Agencje państwowe pomogłyby społeczeństwom i decydentom politycznym, gdyby jasno stawiały sprawę w kwestii tych niepewnych wyników.
Urzędy statystyczne na ogół publikują oficjalne dane statystyczne w postaci szacunków punktowych. W wykorzystywanej przez te urzędy dokumentacji opisującej użyte dane i stosowane metody mogą zawierać się informacje o tym, że wielkości szacunkowe mogą odbiegać od stanu faktycznego, ale zwykle nie podaje się w nich wielkości możliwego błędu. Przy publikacji szacunków w mediach albo w ogóle nie wspomina się o możliwym błędzie, albo robi się to bardzo pobieżnie.
Ponieważ urząd statystyczny nie podaje wskazówek w tej kwestii, korzystający z oficjalnych statystyk mogą źle odczytać dane zawarte w zestawieniach statystycznych. Postuluję, aby urzędy statystyczne dokonywały pomiaru stopnia niepewności i podawały go w publikowanych danych oraz w publikacjach poświęconych kwestiom technicznym.
Dlaczego informowanie o stopniu niepewności oficjalnych danych statystycznych miałoby być ważną sprawą? Najogólniej z tego powodu, że rządy, przedsiębiorstwa i jednostki wykorzystują te dane, podejmując wiele decyzji. Decyzje te mogą być gorsze, gdy podejmujący je błędnie uznają, że dane statystyczne oddają stan faktyczny, albo błędnie zakładają wielkość możliwego błędu. Np. bank centralny może źle ocenić sytuację gospodarczą, a przez to obrać niewłaściwą politykę pieniężną. Gdyby urząd statystyczny informował, że trzeba się liczyć z niepewnością danych, umożliwiłby podejmującym decyzje lepsze zrozumienie faktycznie dostępnych informacji co do zasadniczych zmiennych gospodarczych.
Błąd próby w przypadku danych statystycznych opracowanych na podstawie ankiet można zmierzyć za pomocą stosowanych od dawna zasad statystycznych. Problemem jest to, jak w sposób zadowalający dokonać pomiaru błędu niezwiązanego z próbą. Jest wiele przyczyn takich błędów, a do tego brak zgody co do tego, jak je mierzyć. W moim przekonaniu użyteczne jest rozróżnienie na przejściową niepewność statystyczną, trwałą niepewność statystyczną oraz niepewność konceptualną.
Do przejściowej niepewności statystycznej dochodzi, ponieważ zebranie danych wymaga czasu. Niekiedy urzędy statystyczne publikują wstępne szacunki we wczesnej fazie procesu zbierania danych, po czym dokonują korekty tych szacunków, gdy napłyną nowe dane. Tak więc niepewność może być znaczna wcześnie, ale się zmniejszy, gdy zbierze się więcej danych.
Do trwałej niepewności statystycznej dochodzi przez to, że dane są niepełne lub zbiera się je niewłaściwie, przy czym niepewność ta nie maleje z upływem czasu. Gdy dane uzyskuje się poprzez ankiety, znaczna trwała niepewność może wynikać z tego, że nie reagują ci, do których skierowano pytania, a także z tego, że część respondentów może podać niedokładne dane.
Niepewność konceptualna wynika z niepełnego zrozumienia informacji podawanych w oficjalnych statystykach co do dobrze zdefiniowanych pojęć ekonomicznych bądź z tego, że same pojęcia nie są dostatecznie jasne. Tak więc niepewność konceptualna dotyczy nie tyle wielkości podawanych w statystykach, lecz interpretacji tych danych. Warto przyjrzeć się każdej z tych form niepewności i omówić strategie pomiaru i komunikacji.
Przejściowa niepewność
W USA Biuro Analiz Gospodarczych (BEA) publikuje różnorodne zestawienia szacunków kwartalnych wielkości PKB. Do sporządzenia szacunków wstępnych wykorzystuje się dane dostępne miesiąc po zakończeniu danego kwartału oraz ekstrapolacje wyznaczające tendencję. Drugie i trzecie szacunki publikuje się po dwóch i trzech miesiącach, kiedy dostępne są nowe dane. Pierwsze roczne szacunki zostają opublikowane latem, na podstawie większego zbioru danych, zbieranego co rok. Następnie dokonuje się corocznych korekt oraz korektę pięcioletnią.
Analitycy z BEA bardzo pozytywnie wypowiadali się o dokładności danych dotyczących PKB. Steven Landefeld, Eugene Seskin i Barbara Fraumeni piszą następująco: „W porównaniu z danymi publikowanymi przez inne państwa należy stwierdzić, że amerykańskie rachunki dochodu narodowego spełniają lub przewyższają przyjmowane na świecie kryteria dotyczące dokładności i porównywalności. Szacunkowe wielkości amerykańskiego realnego PKB okazują się przynajmniej równie dokładne (na podstawie porównania z korektami PKB różnych państw) co odpowiednie szacunki publikowane przez inne najważniejsze państwa rozwinięte” (zob. Taking the Pulse of the Economy: Measuring GDP, „Journal of Economic Perspectives”, 22/2008, 193-216; cytowane zdania znajdują się na s. 213).
Dean Croushore wypowiada się znacznie ostrożniej: „Do niedawna specjaliści zajmujący się makroekonomią zakładali, że korekty danych są niewielkie, do tego będąc konsekwencją przypadku, toteż w ogóle nie wpływają na tworzenie modeli strukturalnych, analizy polityki czy prognozy. Badania prowadzone na bieżąco wykazały jednak, że to założenie jest błędne, a korekty danych mają duże znaczenie z wielu nieoczekiwanych powodów” (zob. Frontiers of Real-Time Data Analysis, „Journal of Economic Literature”, 49/2011, s. 72–100; przytoczone zdania są na s. 73).
Pomiar przejściowej niepewności szacunków PKB jest prosty, jeśli można wiarygodnie zakładać, że proces korekty cechuje się jednorodnością czasową. Wówczas można dokonać ekstrapolacji historycznych danych dotyczących rewizji, aby dokonać pomiaru niepewności przyszłych korekt. Prosta ekstrapolacja polegałaby na przypuszczeniu, że utrzyma się rozkład empiryczny korekt.
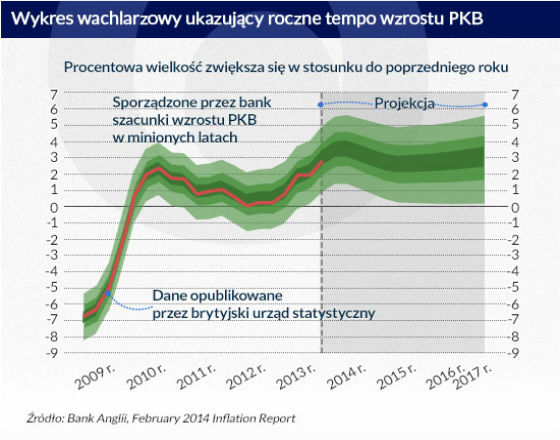
Warto wziąć pod uwagę publikowane regularnie przez Bank Anglii wykresy wachlarzowe. Niżej zamieszczono wykres ukazujący roczne tempo wzrostu PKB, zamieszczony w raporcie poświęconym inflacji z lutego 2014 r. (February 2014 Inflation Report). Część wykresu ukazująca wzrost od ostatnich miesięcy 2013 r. to probabilistyczna prognoza wyrażająca niepewność działającej przy tym banku Komisji ds. Polityki Pieniężnej co do przyszłego wzrostu PKB. Część ukazująca wzrost od 2009 r. do połowy 2013 r. to probabilistyczna prognoza wyrażająca niepewność co do korekt, które brytyjski urząd statystyczny wniesie później do własnych szacunków PKB w minionych okresach. Bank wyjaśnia to następująco: „Na wykresie ukazującym PKB rozkład widoczny po lewej stronie pionowej przerywanej linii odzwierciedla prawdopodobieństwo korekt danych dotyczących minionych okresów” (s. 7).
Należy zwrócić uwagę na wynikającą z tego wykresu znaczną niepewność co do wzrostu PKB w latach 2010–2013. Tak więc Bank Anglii uznaje, że przyszłe korekty szacunków PKB w minionych okresach mogą być poważne.
(infografika Dariusz Gązczyk)
Trwała niepewność
Co roku amerykańskie Biuro Spisu Ludności publikuje dane statystyczne dotyczące rozkładu dochodów gospodarstw domowych. Statystyki te są sporządzone na podstawie informacji o dochodach zebranych podczas uzupełniania bieżącego badania populacji. Znaczna część ankietowanych nie udziela odpowiedzi.
W latach 2002–2012 od 7 proc. do 9 proc. badanych gospodarstw domowych nie podało informacji o dochodzie, nie odpowiadając na pytania z całej części ankiety, a od 41 proc. do 47 proc. badanych gospodarstw domowych podało dane niepełne, gdyż nie odpowiedziało na pojedyncze pytania. Mimo to publikacje Biura Spisu Ludności sprawiają wrażenie, że statystyki dotyczące rozkładu dochodów są dokładne.
Aby sporządzić szacunki punktowe, Biuro Spisu Ludności stosuje imputację typu hot deck, twierdząc następująco: „Przy zastosowaniu tej metody przydziela się brakującą wartość z zapisu o podobnych cechach. Na tym polega typ hot deck. Wielkości hot deck są określone przez takie zmienne, jak wiek, rasa i płeć. Inne cechy wykorzystywane w metodzie hot deck są różne, zależąc od charakteru pytania, na które nie udzielono odpowiedzi. Np. większość pytań skierowanych do osób pracujących dotyczy wieku, pochodzenia rasowego, płci, a sporadycznie zadaje się pytania o inną rzecz związaną z siłą roboczą, np. zatrudnienie w pełnym lub niepełnym wymiarze godzin” (US Census Bureau, Current Population Survey Design and Methodology, analiza techniczna nr 66, Washington 2006, s. 9–2).
W dokumentacji bieżących badań populacji nie zamieszcza się dowodów, że metoda hot deck daje rozkład brakujących danych zbliżony do rozkładu faktycznego. W innym dokumencie opublikowanym przez Biuro Spisu Ludności, opisującym badania dotyczące sytuacji mieszkaniowej, zamieszczono wiele ujawniające zdania: „Niektórzy odmawiają podania informacji albo nie znają odpowiedzi. Gdy brakuje wszystkich odpowiedzi, inne, podobne do nich zapisy zastępują dane brakujące. […] W przypadku większości brakujących odpowiedzi kopiuje się odpowiedź udzieloną przez podobne gospodarstwo domowe. Biuro Spisu Ludności nie wie, w jakim stopniu wartości imputowane są zbliżone do faktycznych” (US Census Bureau, Current Housing Reports, Series H150/09, American Housing Survey for the United States: 2009, Washington 2011, s. D-2).
Podczas badań ekonometrycznych wykazano, jak należy mierzyć niepewność wynikającą z braku odpowiedzi, nie dokonując przy tym założeń co do charakteru brakujących danych. Bierze się pod uwagę wszystkie możliwe wielkości brakujących danych. Następnie na podstawie danych wyznacza się szacunki przedziałowe oficjalnych statystyk. W piśmiennictwie wyznacza się te wielkości przedziałowe dla średnich populacji, kwantyli i innych parametrów. W poświęconych tym zagadnieniom publikacjach wykazuje się także, jak wyznaczać przedziały ufności, które wraz z wielkościami przedziałowymi pozwolą ustalić błąd próby i błąd wynikający z braku odpowiedzi.
Aby to zilustrować, wykorzystałem dane Biura Spisu Ludności, aby określić szacunki przedziałowe dochodu gospodarstwa domowego wyznaczonego przez medianę oraz odsetek rodzin o dochodzie poniżej progu nędzy w latach 2001–2011. W przypadku jednego zbioru szacunków bierze się pod uwagę wyłącznie sytuacje, kiedy ankietowani nie odpowiadają na pojedyncze pytania, w przypadku drugiego zbioru – również sytuacje, kiedy nie odpowiadają na pytania z całej części ankiety. Szacunki te ukazują, że w sytuacji, kiedy ankietowani nie odpowiadają na pojedyncze pytania, może powstać wielki problem przy wnioskowaniu, jak przedstawia się rozkład dochodów amerykańskich gospodarstw domowych. Gdy ankietowani nie odpowiadają na pytania z całej części ankiety, problem ten staje się jeszcze poważniejszy.
Niepewność pojęciowa przy korekcie sezonowej
Gdy spogląda się z dostatecznie dużej wysokości, cel korekty sezonowej oficjalnych statystyk wydaje się oczywisty. Amerykańskie Biuro Statystyk Rynku Pracy następująco tłumaczy korektę sezonową statystyk zatrudnienia: „Na czym polega korekta sezonowa? Korekta sezonowa to technika statystyczna, która ma być próbą pomiaru wpływu przewidywalnych czynników sezonowych oraz usunięcia tego wpływu, aby ukazać, jak zatrudnienie i bezrobocie zmieniają się z miesiąca na miesiąc”.
Z poziomu parteru trudniej dostrzec, jak należałoby przeprowadzić korektę sezonową. Amerykańskie urzędy statystyczne stosują metodę X-12-ARIMA. Być może X-12 to złożony i udany algorytm. Może być jednak i tak, że to niezgłębiona czarna skrzynka zawierająca złożony zestaw operacji statystycznych bez podstaw ekonomicznych. Jonathan H. Wright tak oto pisze o trudności wynikającej z takiego rozumienia X-12: „Większość teoretyków uważa korektę sezonową za bardzo przyziemne zadanie. Mówi się, że robią to żyjące w norach hobbity. W moim przekonaniu to wielka pomyłka”. Następnie dodaje: „Korekta sezonowa powoduje niezmiernie istotne konsekwencje”
Nie ma obecnie ewidentnie właściwej metody pomiaru niepewności związanej z korektą sezonową. X-12 to algorytm, nie metoda mająca za podstawę dobrze określoną dynamiczną teorię gospodarki. Nie jest oczywiste, jak należy oceniać stopień, w którym osiąga się cel polegający na usunięciu wpływu przewidywalnych zjawisk sezonowych. Przypuszczalnie można porównywać wyniki uzyskane za pomocą X-12 z wynikami innych zaproponowanych algorytmów. Po wykonaniu korekty sezonowej za pomocą każdego z tych algorytmów zakres uzyskanych szacunków należy uznać za miarę niepewności pojęciowej.
Radykalniejszym odejściem od obecnie stosowanej metody byłoby odrzucenie korekty sezonowej i pozostawienie tym, którzy korzystają z oficjalnych statystyk, decyzji, jak interpretować niekorygowane dane. Analiza niekorygowanych danych powinna być szczególnie wartościowa dla tych użytkowników statystyk, którzy chcą oceniać sytuację gospodarczą raczej na podstawie rocznych niż miesięcznych wskaźników.
Przypuśćmy, że ktoś chce porównać bezrobocie w marcu 2013 r. i w marcu 2014 r. Można twierdzić, że rozsądniej jest porównywać nieskorygowane szacunki dotyczące tych miesięcy niż wielkości szacunkowe po korekcie sezonowej. Niekorygowane szacunki sporządza się na podstawie danych faktycznie zebranych w tych dwóch interesujących kogoś miesiącach.
Natomiast wielkości szacunkowe dotyczące marca 2013 r. i marca 2014 r. po korekcie sezonowej sporządza się na podstawie danych zebranych nie tylko w tych miesiącach, lecz w dłuższym okresie przed nimi.
Zaproponowałem metody pomiaru przejściowej niepewności statystycznej w przypadku szacunkowych wielkości z oficjalnych statystyk sporządzanych na podstawie niepełnych danych oraz trwałej niepewności statystycznej wynikającej z braku odpowiedzi przy prowadzeniu badań na podstawie ankiet. Zwracałem również uwagę na niepewność pojęciową w przypadku korekty sezonowej. Byłoby lepiej, gdyby urzędy statystyczne informowały decydentów politycznych i społeczeństwo, jeśli mierzą te oraz inne znaczące niepewności i podają takie dane w oficjalnych statystykach. Nalegam, aby tak postępowały.
Otwartą kwestią jest to, jak informowanie o niepewności danych wpłynęłoby na procesy decyzyjne w polityce i na decyzje jednostek. Obecnie bardzo mało wiemy o tym, jak interpretują dane ci, którzy korzystają z oficjalnych statystyk. Nie wiemy także, jak zmieniłoby się podejmowanie decyzji, gdyby urzędy statystyczne regularnie i wyraźnie informowały o niepewności. Zachęcam naukowców badających zachowanie i prowadzących badania socjologiczne, aby zapoczątkowali badania empiryczne, które pozwoliłyby poznać te kwestie.
Charles F. Manski jest profesorem ekonomii, wykłada na Northwestern University.
Artykuł po raz pierwszy ukazał się w VoxEU.org (tam dostępna jest pełna bibliografia) i można go przeczytać tutaj. Tłumaczenie i publikacja za zgodą wydawcy
ChatGPT zapoczątkował nowy etap automatyzacji. W nadchodzących latach generatywna sztuczna inteligencja może doprowadzić do głębokich zmian na rynku pracy oraz znacząco przyspieszyć wzrost gospodarczy.
Droga energia, slowbalizacja, brak rąk do pracy, nadmierna biurokracja, wieloletnie zaniedbania inwestycyjne oraz opóźnienia technologiczne spętały potencjał rozwojowy Niemiec. Gospodarka przechodzi przez polikryzys– spowodowany wieloma czynnikami – na który nie ma prostej odpowiedzi w postaci np. pakietu koniunkturalnego lub jednej, porządnej reformy. RFN potrzebuje w istocie polireformy – dziesiątków drobnych korekt, które jednak jako całość określą na nowo równowagę między rynkiem a państwem.
Ceny konsumpcyjne rosły w Stanach Zjednoczonych w tempie 3,5 proc., co stawia pod dużym znakiem zapytania perspektywę cięcia stóp procentowych za Oceanem. Odczyt inflacji CPI za marzec 2024 r. w USA był nieznacznie wyższy od rynkowego konsensusu i postawił Komitet Otwartego Rynku w niełatwym położeniu.
Oczekiwaniom inflacyjnym gospodarstw domowych zazwyczaj nie poświęca się zbytniej uwagi przy monitorowaniu i prognozowaniu inflacji, częściowo dlatego, że wykazano, iż mediana ich oczekiwań ma mniejszą moc predykcyjną niż oczekiwania innych podmiotów. Niniejszy artykuł ma na celu dowieść, że zmiany w rozkładzie oczekiwań inflacyjnych gospodarstw domowych są istotne dla prognozowania inflacji w najbliższym czasie i oferują dodatkowe informacje w porównaniu z miernikami rynkowymi i oczekiwaniami prognostów. Sugeruje to, że oczekiwania inflacyjne gospodarstw domowych powinny odgrywać większą rolę w monitorowaniu inflacji, a w konsekwencji w kształtowaniu polityki pieniężnej.
W niedawnych badaniach zasugerowano, że wynagrodzenia poniżej prawnie ustalonej płacy minimalnej są zaskakująco powszechnym zjawiskiem. W niniejszym artykule omówiono tzw. „kradzież płac” w Stanach Zjednoczonych oraz jej wpływ na wzrost wynagrodzeń, który mógłby być udziałem pracowników.
Najnowsze wydanie „Obserwatora Finansowego” ukazuje nam wizje przyszłości bliskiej i dalekiej. W tym numerze, najlepsi eksperci postarają się odpowiedzieć na kilka kluczowych pytań, dotyczących sztucznej inteligencji i tego jak generatywna AI wpłynie na bankowość, edukację oraz inne dziedziny naszego życia.
Nieefektywność nadzoru prowadzi do występowania nieprawidłowości i nadużyć na rynku funduszy inwestycyjnych w Polsce – taką sensacyjną tezę stawiają autorzy monografii „Nieprawidłowości i nadużycia na rynku funduszy inwestycyjnych”.
Budowa Centralnego Portu Komunikacyjnego wzmocniłaby znacznie pozycję Polski w europejskiej gospodarce – stwierdził w rozmowie z „Obserwatorem Finansowym" dr Andreas Wittmer, dyrektor zarządzający Centrum Badań Lotniczych na Uniwersytecie w St. Gallen.
Sztuczna inteligencja powoli zmienia sposób działania banków i instytucji finansowych. Pomaga im zredukować ciężar biurokracji, ale także podejmować szybsze decyzje oraz utrzymywać efektywny kontakt z klientami. A będzie jeszcze lepiej. W perspektywie czeka kilkunastoprocentowy wzrost EBITDA.
Dywersyfikacja metod płatności, rozumiana jako poszerzanie dostępnej ich gamy, zwiększa wybór płatników i odbiorców płatności, stymuluje konkurencję na rynku i innowacyjność dostawców usług płatniczych, redukuje ryzyko, ponieważ uniezależnia rynek płatności od jednego, potencjalnie dominującego systemu płatności. Podobnie ma się sprawa z formami pieniądza, które się uzupełniają a jednocześnie konkurują i substytuują wzajemnie.
Współczesne problemy prawne Unii Europejskiej, sztuczna inteligencja w bankowości oraz polityka pieniężna były tematami grudniowego zjazdu na podyplomowych studiach MBA organizowanych w ramach drugiej edycji projektu „Akademia NBP”.
Portal ekonomiczny NBP „Obserwator Finansowy” ponownie znalazł się w czołówce najbardziej opiniotwórczych mediów w kategorii „Media ekonomiczne i biznesowe”, wyprzedzając m.in. „Parkiet”. Wzrost cytowalności treści publikowanych na łamach serwisu wzrósł w kwietniu w odniesieniu do marca 2023 r. o 37 proc.
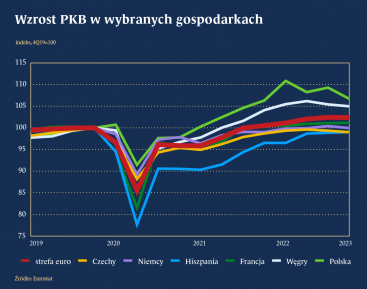
Sytuacja gospodarcza w Polsce na tle innych krajów przedstawia się korzystnie. Warto zauważyć, że w szybkim tempie nadrabiamy dystans dzielący Polskę od poziomu życia w wybranych państwach europejskich. W ciągu ostatnich czterech lat dynamika wzrostu PKB plasowała Polskę powyżej innych krajów europejskich, zarówno strefy euro, w tym Niemiec i Francji, jak i krajów Unii Europejskiej z własną walutą, np. Czech.
Większość polskich przedsiębiorców odczuła skutki wojny w Ukrainie, choć jej wpływ oceniają w zróżnicowany sposób – wynika z badania przeprowadzonego przez Polski Instytut Ekonomiczny.
W styczniu 2020 roku Wielka Brytania formalnie opuściła Unię Europejską. Oczekiwane korzyści z brexitu, poza odzyskaniem suwerenności w zakresie kształtowania prawa i zewnętrznych relacji gospodarczych, jednak się nie zmaterializowały. Widoczny jest natomiast spadek wydajności i konkurencyjności brytyjskiej gospodarki, co wpływa także na kondycję rynku pracy.