Big data to ropa XXI wieku – głosi slogan, który jednak jest prawdziwy. Zdigitalizowane dane będą siłą napędową wzrostu w przyszłości – wzrostu, którego świat potrzebuje jak płuca powietrza.
Według najpowszechniejszej definicji big data to cyfry, znaki lub symbole, które mogą być przechowywane i przesyłane w postaci sygnałów elektrycznych oraz zapisywane na magnetycznych, optycznych lub mechanicznych nośnikach. Jak wskazuje nazwa, mówimy o tak wielkich zbiorach danych, że tradycyjne narzędzia obliczeniowe, jak choćby komputerowy arkusz kalkulacyjny, nie znajdują do nich zastosowania.
Te kolosalne zbiory danych są zarazem substratem i produktem interakcji technologicznych w świecie cyfrowym. Za geometryczną dynamiką ich przyrostu (średnio ponad 200 proc. rocznie) stoi ekspansja internetu rzeczy oraz kanałów cyfrowych. Każdego dnia tworzymy 2,5 tryliona bajtów danych. Szacuje się, że w 2025 r. wolumen globalny big data wyniesie ponad 175 zetabajtów. Równolegle do gospodarki cyfrowej rozwija się gospodarka oparta na danych.
Jak okiełznać chaos
W ogólnej masie danych odnajdujemy te ustrukturyzowane w tradycyjnych bazach danych wierszowo-kolumnowych oraz te nieustrukturyzowane, bez przejrzystego formatu przechowywania. Te drugie stanowią zdecydowaną większość, bo aż 80 proc. wszystkich zakumulowanych danych, i do niedawna niewiele można było z nimi zrobić. Zarówno jedne, jak i drugie mają dwa źródła – maszyny i ludzie. W przypadku danych ustrukturyzowanych wszystko, co pochodzi z czujników, systemów finansowych, urządzeń medycznych, systemu nawigacji satelitarnej GPS, statystyk użytkowania rejestrowanych przez serwery i aplikacje, platform typu marketplace (zakupy, zwroty, płatności, rejestracje, rezerwacje i subskrypcje), jest klasyfikowane jako dane generowane maszynowo. Pochodną aktywności człowieka są natomiast dane behawioralne (ilustrujące zachowanie w sieci, w tym odwiedzane strony, pobierane aplikacje i ulubione gry) oraz dane demograficzne (wiek, płeć, populacja, rasa, dochód, edukacja, zainteresowania i zatrudnienie).
Dane nieustrukturyzowane pochodzenia maszynowego obejmują zdjęcia satelitarne, sygnały z radarów, taśmy z monitoringu, dane wygenerowane w toku eksperymentów naukowych oraz wszelkie inne zapisy z aparatury rejestrującej zjawiska fizyczne w środowisku naturalnym. Do nieustrukturyzowanych danych, za którymi stoi aktywność człowieka, zalicza się z kolei dane z mediów społecznościowych, dane mobilne i treści ze stron internetowych, w tym zdjęcia, które przesyłamy do serwisów takich jak Facebook lub Instagram, filmy, które oglądamy na YouTubie, wiadomości tekstowe, tweety, polubienia, udostępnienia, komentarze na YouTubie, Facebooku itp.
Idąc dalej, można wyodrębnić trzy strumienie danych. Pierwszym płyną dane tworzone i wykorzystywane przez społeczeństwo obywatelskie oraz środowisko naukowe do monitorowania i analizowania polityki rządu, a także przez osoby fizyczne oczekujące poprawy dostępu do usług publicznych i komercyjnych dostosowanych do ich potrzeb. Drugim – dane generowane lub otrzymywane przez agendy rządowe i organizacje międzynarodowe w celu wsparcia administracji, jakości świadczonych usług i prowadzenia polityki popartej rzetelnymi informacjami. I trzecim – dane generowane przez sektor prywatny. W krajobrazie naznaczonym rewolucją cyfrową ten ostatni strumień kryje największy potencjał w zakresie konwersji na PKB.
Nowy generator wzrostu
Popandemiczne odmrażanie gospodarki uwidacznia zapotrzebowanie na wysokowydajne czynniki wzrostu. Takim akceleratorem są bez wątpienia technologie cyfrowe i towarzyszące im dane. Transformacja cyfrowa jest wszędzie na świecie sztandarowym hasłem planów odbudowy gospodarczej. Chodzi o przestawienie całych gałęzi przemysłu na tory generowania i monetyzowania danych. Wzrostotwórczy potencjał danych czyni je wirtualnym surowcem, który decyduje o uzyskiwaniu przewagi konkurencyjnej. Zastosowane w biznesie pozwalają poprawiać jakość istniejących produktów i usług, redukować koszty produkcji i transakcji, rozwijać innowacyjne produkty i usługi, podejmować trafniejsze decyzje, skuteczniej docierać do konsumentów poszukujących określonego rodzaju towarów i usług. W skali makro wykorzystanie danych pomaga niwelować niedoskonałości rynku i pozytywnie wpływa na wydajność, wzrost, zatrudnienie, a ostatecznie – dobrobyt.
W skali makro wykorzystanie danych pomaga niwelować niedoskonałości rynku i pozytywnie wpływa na wydajność, wzrost i zatrudnienie.
Obecnie dane są przede wszystkim katalizatorem produktywności: w zespoleniu z technologią umożliwiają efektywniejsze wykorzystanie czynników produkcji poprzez usprawnienie procesów biznesowych, czerpanie wiedzy o potrzebach klientów, opracowywanie nowych produktów lub podejmowanie decyzji popartych faktami, nie intuicją. Z czasem, w miarę przezwyciężania przeszkód prawnych, rozwiną się regularne rynki danych, a to uczyni z big data czynnik produkcji – na równi z pracą, kapitałem i ziemią.
Ten wyścig zaczął się już długo przed pandemią, ale nie wszyscy zrozumieli jego stawkę. Wygrają ci, którzy najwcześniej uznali imperatyw cyfryzacji i uczynili go filarem strategii biznesowej. Blisko półtoraroczny lockdown przetrzebił niektóre branże. Powrót do stanu sprzed pandemii, o ile jesienią nie doświadczymy kolejnej fali, zajmie kilkanaście miesięcy. Ważne, by ten czas poświęcić nie tylko na odrabianie strat bilansowych, lecz także znaleźć środki na inwestycje w technologie przetwarzania danych, o których wiadomo, że będą motorem wzrostu w tej dekadzie. Inwestowanie w gospodarkę opartą na danych to także unikalna szansa na przezwyciężenie pułapki średniego wzrostu i bodziec dla krajów rozwijających się.
Monetyzacja teoretycznie prosta
Dane są nieustannie generowane pasywnie w toku działalności gospodarczej. Wszyscy tworzymy tzw. ślady cyfrowe. Na początku tego łańcucha znajdują się dane z pierwszej ręki, czyli dane własne. Firmy czerpią je z plików cookies na swoich stronach internetowych i w aplikacjach mobilnych, ze statystyk zakupowych, baz CRM, ankiet zwracanych przez klientów, centrum obsługi klienta, słowem – wszelkich informacji pozostawionych przez użytkowników. Dane pozyskane w ten sposób są produktem ubocznym, wykorzystywanym do tworzenia nowych lub udoskonalania istniejących produktów lub usług. Z oczywistych względów zakres danych z pierwszej ręki jest ograniczony do sfery działalności danej firmy. Sposobem na pokonanie ograniczeń skali danych własnych jest korzystanie z danych pozyskiwanych od innych firm (tzw. dane z drugiej ręki) w ramach dwustronnych umów handlowych. Na przykład operatorzy kart kredytowych udostępniają dane dotyczące transakcji w określonych lokalizacjach biurom podróży, a hotele wymieniają się informacjami z liniami lotniczymi.
Wreszcie mamy dane z trzeciej ręki. Są one bodaj najszerzej dostępne jako produkt docelowy instytucji, które programowo agregują dane do celów statystycznych, sondażowych, ratingowych. Podmioty je zbierające czerpią z różnych źródeł i nie mają zwykle styczności z konsumentami. Ten pośredni charakter – fakt, że nie pochodzą one z bezpośredniej relacji – jest nieodłączną wadą danych z trzeciej ręki.
Bezpośrednia monetyzacja ma miejsce, gdy firma sprzedaje swoje dane – surowe albo przetworzone, np. listy kontaktów potencjalnych przedsięwzięć biznesowych – lub ustalenia, które mają wpływ na branże i firmy nabywców. Pośrednia monetyzacja polega natomiast na wnikliwej analizie danych, która prowadzi do konkretnych wniosków biznesowych, mających przełożenie na optymalizację procesów. Dane mogą podpowiedzieć, w jaki sposób dotrzeć do klientów i zrozumieć ich zachowanie, dzięki czemu można zwiększyć sprzedaż. Mogą również wskazać, gdzie i jak poczynić oszczędności. Brak odpowiedniej strategii pośredniego monetyzowania danych naraża firmę na utratę cennych informacji.
Sześć przeszkód
Dane same w sobie nie są ani dobrem prywatnym, ani dobrem publicznym, choć z każdym z nich dzielą jedną cechę. Podobnie jak dobra prywatne, są wykluczalne, czyli dostępne tylko tym, którzy płacą za konsumpcję. Z dobrami publicznymi łączy je natomiast niekonkurencyjność – właściwość, która oznacza, że konsumpcja przez jeden podmiot nie powoduje zmniejszenia podaży i nie stanowi przeszkody do jednoczesnej, równowartościowej konsumpcji przez inne podmioty.
Nieprzetworzone dane powinny być wolno dostępne jako budulec gospodarki cyfrowej. Wciąż jednak mamy do czynienia z odizolowanymi systemami gromadzenia danych, które tworzą niedostępne silosy. Aby dane stały się w pełni przydatne, trzeba ustalić normy dotyczące obrotu nimi. W niektórych segmentach rynku prężnie funkcjonuje dwustronna wymiana danych. Flagowym przykładem jest handel danymi pod – znienawidzoną przez wielu internautów – reklamę targetowaną behawioralnie. Nie istnieją natomiast otwarte wielostronne rynki danych, a próby ich stworzenia kończyły się dotychczas niepowodzeniem. Wspomniana wyżej wykluczalność danych sugeruje, że doskonale nadają się one do spieniężania w handlu. A jednak firmy nie palą się do sprzedawania danych ani wymieniania się nimi na zasadach rynkowych. Jakie są tego powody?
Problem z godziwą wyceną (zob. niżej).
Brak ustandaryzowanego i bezpiecznego mechanizmu udostępniania danych.
Obawa, że udostępnienie danych może skutkować utratą ich ukrytego, jeszcze niespenetrowanego potencjału: przy zaawansowanych metodach rafinowania danych przy użyciu sztucznej inteligencji może się teoretycznie zdarzyć, że wartość przyszłych wtórnych zastosowań danych znacznie przewyższy wartość ich pierwotnego czy obecnego wykorzystania, a wówczas podmioty ponoszące koszty zbierania danych niekoniecznie będą tymi, które w pełni zdyskontują ich wartość.
Obawa, że pozornie „niegroźne” dane, pozyskane jako produkt uboczny prowadzonej działalności, trafią okrężną drogą do konkurencji i przyniosą jej wymierne korzyści.
Chęć zachowania korzyści skali, wynikających z przechowywania danych. Na przykład w dziedzinie sztucznej inteligencji wielkość zbiorów danych jest wyznacznikiem dokładności algorytmów predykcyjnych. Głębokie uczenie (ang. deep learning – DL), najbardziej zaawansowana technika sztucznej inteligencji, konsumuje dużo większe zbiory danych niż tradycyjne uczenie maszynowe (ang. machine learning – ML). Oprócz korzyści skali dane niosą ze sobą także korzyści zakresu: połączenie różnych typów danych może dostarczyć informacji, które byłyby niedostępne dla jednego typu danych.
Brak zachęt czy wręcz norm prawnych dotyczących odpłatnego dzielenia się danymi.
Nie istnieją otwarte wielostronne rynki danych, a próby ich stworzenia kończyły się dotychczas niepowodzeniem.
Na osobne omówienie zasługuje wielce złożona kwestia wyceny danych. Niekonkurencyjność danych, czyli ów nieograniczony potencjał wielokrotnego replikowania, w połączeniu z brakiem jednolitej metodologii wyceny sprawia, że trudno przypisać im określoną wartość ekonomiczną. Zakładając, że surowe dane tworzą wartość po przetworzeniu i wydobyciu z nich wniosków, można sumować koszty poszczególnych kroków w łańcuchu wartości informacji; można szacować korzyści ekonomiczne, jakie przynoszą dane; można wreszcie opierać się na wartości giełdowej spółek intensywnie korzystających z danych i wartości transakcji przejęć aktywów tego rodzaju.
Jednym z wyznaczników wartości jest jakość, ale tę w przypadku danych trudno z góry ocenić, gdyż podobnie jak informacje, należą one do dóbr doświadczalnych. Z pomocą przyszłaby certyfikacja danych przez dostawców, wskazująca ich pochodzenie i tym samym świadcząca o ich jakości. Opierając się na reputacji źródła, nabywcy mieliby minimum pewności, że nie kupują kota w worku, lecz wartościowy towar. Tu jednak pojawiają się problemy regulacyjne. Po pierwsze, metadane potrzebne do ustalenia pochodzenia mogą same w sobie podlegać ograniczeniom prawnym z uwagi na ochronę prywatności. Po drugie, kto kontrolowałby prawidłowość certyfikowania danych przez dostawców? Nietrudno wyobrazić sobie nagminne praktyki ukrywania lub manipulowania takimi informacjami. I po trzecie, siły rynkowe będą dążyły do koncentracji sektora danych, co utrudni konkurencję. Już dziś największe wolumeny danych są w rękach kilku gigantów.
Aby zbudować płynne rynki danych, które będą cieszyły się zaufaniem kontrahentów, konieczny jest konsensus międzynarodowy, porządkujący zagadnienia prawa własności i jakości danych oraz liberalizujący globalny obrót surowymi danymi. Być może nadszedł też czas, by w umowach o wolnym handlu zawierać klauzule o swobodnym przepływie danych nieosobowych. To także wymaga współpracy na rzecz porozumienia na forum organizacji wielostronnych.
Mimo wysokiego poziomu wykształcenia technicznego w Rosji innowacyjność jej sektora technologicznego jest stosunkowo niska. Jedną z istotnych przyczyn tej sytuacji jest trwająca od wielu lata migracja specjalistów, którą wojna znacznie przyśpiesza.
ChatGPT zapoczątkował nowy etap automatyzacji. W nadchodzących latach generatywna sztuczna inteligencja może doprowadzić do głębokich zmian na rynku pracy oraz znacząco przyspieszyć wzrost gospodarczy.
Produkcja ropy na Alasce znalazła się na poziomie najniższym od 45 lat. Ludzie wyjeżdżają stamtąd. Stan ma problemy budżetowe, które będzie chciał załatać m.in. uruchomieniem sprzedaży kredytów węglowych.
Droga energia, slowbalizacja, brak rąk do pracy, nadmierna biurokracja, wieloletnie zaniedbania inwestycyjne oraz opóźnienia technologiczne spętały potencjał rozwojowy Niemiec. Gospodarka przechodzi przez polikryzys– spowodowany wieloma czynnikami – na który nie ma prostej odpowiedzi w postaci np. pakietu koniunkturalnego lub jednej, porządnej reformy. RFN potrzebuje w istocie polireformy – dziesiątków drobnych korekt, które jednak jako całość określą na nowo równowagę między rynkiem a państwem.
Ceny konsumpcyjne rosły w Stanach Zjednoczonych w tempie 3,5 proc., co stawia pod dużym znakiem zapytania perspektywę cięcia stóp procentowych za Oceanem. Odczyt inflacji CPI za marzec 2024 r. w USA był nieznacznie wyższy od rynkowego konsensusu i postawił Komitet Otwartego Rynku w niełatwym położeniu.
Oczekiwaniom inflacyjnym gospodarstw domowych zazwyczaj nie poświęca się zbytniej uwagi przy monitorowaniu i prognozowaniu inflacji, częściowo dlatego, że wykazano, iż mediana ich oczekiwań ma mniejszą moc predykcyjną niż oczekiwania innych podmiotów. Niniejszy artykuł ma na celu dowieść, że zmiany w rozkładzie oczekiwań inflacyjnych gospodarstw domowych są istotne dla prognozowania inflacji w najbliższym czasie i oferują dodatkowe informacje w porównaniu z miernikami rynkowymi i oczekiwaniami prognostów. Sugeruje to, że oczekiwania inflacyjne gospodarstw domowych powinny odgrywać większą rolę w monitorowaniu inflacji, a w konsekwencji w kształtowaniu polityki pieniężnej.
Najnowsze wydanie „Obserwatora Finansowego” ukazuje nam wizje przyszłości bliskiej i dalekiej. W tym numerze, najlepsi eksperci postarają się odpowiedzieć na kilka kluczowych pytań, dotyczących sztucznej inteligencji i tego jak generatywna AI wpłynie na bankowość, edukację oraz inne dziedziny naszego życia.
Nieefektywność nadzoru prowadzi do występowania nieprawidłowości i nadużyć na rynku funduszy inwestycyjnych w Polsce – taką sensacyjną tezę stawiają autorzy monografii „Nieprawidłowości i nadużycia na rynku funduszy inwestycyjnych”.
Budowa Centralnego Portu Komunikacyjnego wzmocniłaby znacznie pozycję Polski w europejskiej gospodarce – stwierdził w rozmowie z „Obserwatorem Finansowym" dr Andreas Wittmer, dyrektor zarządzający Centrum Badań Lotniczych na Uniwersytecie w St. Gallen.
Sztuczna inteligencja powoli zmienia sposób działania banków i instytucji finansowych. Pomaga im zredukować ciężar biurokracji, ale także podejmować szybsze decyzje oraz utrzymywać efektywny kontakt z klientami. A będzie jeszcze lepiej. W perspektywie czeka kilkunastoprocentowy wzrost EBITDA.
Dywersyfikacja metod płatności, rozumiana jako poszerzanie dostępnej ich gamy, zwiększa wybór płatników i odbiorców płatności, stymuluje konkurencję na rynku i innowacyjność dostawców usług płatniczych, redukuje ryzyko, ponieważ uniezależnia rynek płatności od jednego, potencjalnie dominującego systemu płatności. Podobnie ma się sprawa z formami pieniądza, które się uzupełniają a jednocześnie konkurują i substytuują wzajemnie.
Współczesne problemy prawne Unii Europejskiej, sztuczna inteligencja w bankowości oraz polityka pieniężna były tematami grudniowego zjazdu na podyplomowych studiach MBA organizowanych w ramach drugiej edycji projektu „Akademia NBP”.
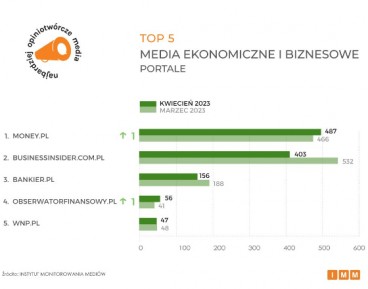
Portal ekonomiczny NBP „Obserwator Finansowy” ponownie znalazł się w czołówce najbardziej opiniotwórczych mediów w kategorii „Media ekonomiczne i biznesowe”, wyprzedzając m.in. „Parkiet”. Wzrost cytowalności treści publikowanych na łamach serwisu wzrósł w kwietniu w odniesieniu do marca 2023 r. o 37 proc.
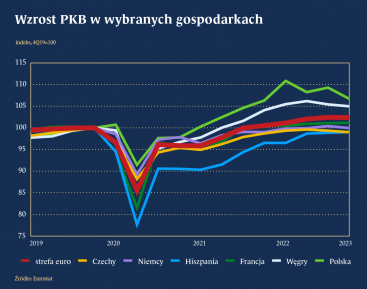
Sytuacja gospodarcza w Polsce na tle innych krajów przedstawia się korzystnie. Warto zauważyć, że w szybkim tempie nadrabiamy dystans dzielący Polskę od poziomu życia w wybranych państwach europejskich. W ciągu ostatnich czterech lat dynamika wzrostu PKB plasowała Polskę powyżej innych krajów europejskich, zarówno strefy euro, w tym Niemiec i Francji, jak i krajów Unii Europejskiej z własną walutą, np. Czech.
Większość polskich przedsiębiorców odczuła skutki wojny w Ukrainie, choć jej wpływ oceniają w zróżnicowany sposób – wynika z badania przeprowadzonego przez Polski Instytut Ekonomiczny.
W styczniu 2020 roku Wielka Brytania formalnie opuściła Unię Europejską. Oczekiwane korzyści z brexitu, poza odzyskaniem suwerenności w zakresie kształtowania prawa i zewnętrznych relacji gospodarczych, jednak się nie zmaterializowały. Widoczny jest natomiast spadek wydajności i konkurencyjności brytyjskiej gospodarki, co wpływa także na kondycję rynku pracy.