Sztuczna inteligencja nie gra w kości. Na razie gra w piłkę
Bóg nie gra w kości – pisał Albert Einstein rozważając niedeterministyczny model świata, jaki wynikał z odkrywanych wówczas zasad mechaniki kwantowej. Współcześnie sztuczna inteligencja dobrze radzi sobie w środowiskach o ustalonych regułach – jak szachy – ale gorzej, gdy wkracza przypadkowość.
(Envato)
Programiści szukają więc sposobów, by nauczyć maszyny działania w otoczeniu, w którym związek między działaniem a jego skutkiem nie zawsze da się ze 100-procentowym prawdopodobieństwem przewidzieć, gdyż swoją rolę odgrywa przypadek. I między innymi w tym celu dr Karol Kurach, wraz z zespołem, stworzył środowisko do trenowania sztucznej inteligencji pod nazwą Google Research Football (GRF). Kurach pracuje w Google Brain, czyli komórce informatycznego giganta, która prowadzi badania nad sztuczną inteligencją. Jednak w przeciwieństwie do innych zespołów, może pozwolić sobie na – nietypowe dla korporacji – badania o długim horyzoncie, niepowiązane z konkretnym produktem.
GRF wygląda jak typowa gra wideo, w której gracz może sterować piłkarzem jednej z drużyn i mierzyć się z komputerowym przeciwnikiem. Różnica jest taka, że w tym przypadku graczem jest ucząca się sztuczna inteligencja. Żeby dokładniej zrozumieć ten mechanizm, trzeba najpierw wyjaśnić kilka pojęć.
Agent kontra boty
W podstawowym scenariuszu, w meczu rozgrywanym w GRF między Frequentists United a Real Bayesians (żart zrozumiały dla wąskiej grupy statystyków-kibiców) bierze udział dwudziestu jeden graczy sterowanych przez komputer i jeden… także przez komputer. Tych pierwszych nazywa się botami, a tego ostatniego – agentem. Różnica między botem a agentem leży w algorytmie sterującym jego zachowaniem. Program kierujący botem jest dziełem inżynierii, co oznacza, że każde jego zachowanie jest przewidziane w kodzie napisanym przez programistę, reakcja na ruchy przeciwnika, położenie piłki, itd. Natomiast agentowi człowiek nie podpowiada, kiedy ten ma podać, kiedy strzelić, a kiedy biec – musi się tego nauczyć sam.
Przyszłością sztucznej inteligencji jest uczenie maszynowe.
Obecnie w grach wideo ludzcy gracze mierzą się właśnie z botami. Również działanie robotów, a nawet – w przeważającej większości – samochodów autonomicznych, jest od początku do końca zaprojektowane przez człowieka. Przyszłością sztucznej inteligencji jest jednak uczenie maszynowe, czyli machine learning, a postępy w tej dziedzinie ma wspierać nowe środowisko.
Jak tłumaczy dr Kurach, są trzy podejścia do uczenia maszynowego. Supervised learning i unsupervised learning uczą sztuczną inteligencję działania na zbiorach danych, przekształcania jednych informacji na inne. Choć brzmi prosto, mogą być to bardzo złożone operacje, jak np. w rozpoznawanie obrazów. “W przeciwieństwie do tych typów, reinforced learning jest paradygmatem interaktywnym, u którego podstaw leżą dynamiczne interakcje pomiędzy agentem a otoczeniem. Reinforcement learning jest stosowany w takich dziedzinach, jak kontrola robotów, systemy wieloagentowe czy teoria gier” – wyjaśnia informatyk.
Algorytm, środowisko i sieć neuronowa
Na reinforced learning składają się trzy elementy. Pierwszy to agent, którym może być np. sieć neuronowa. Podobno najłatwiej wyobrazić ją sobie jako graf łączący różne matematyczne przekształcenia, takie jak np. dodawanie czy mnożenie macierzy. Niestety, najłatwiej nie oznacza łatwo. Każdemu połączeniu pomiędzy poszczególnymi punktami sieci przypisana jest jakaś waga. Na podstawie tych wag agent reaguje, gdy układ znajdzie się w określonym stanie.
Drugim składnikiem jest środowisko – co jest w nim możliwe, a co nie, jakie są dostępne dla agenta akcje, a także system nagród i kar. Każda sieć neuronowa dąży bowiem do maksymalizacji nagrody. Środowiskiem mogą być np. szachy, planszowa gra „go”, a nawet gry Atari, które święciły popularność na początku ery komputerowej rozrywki, jak np. Breakout, Pacman czy Space Invaders. Wszystkie one mają swoje reguły, określony zasób możliwych do podjęcia działań, a także cel, czyli wygranie partii lub dojście do końca etapu.
Spoiwem dla tych elementów jest algorytm uczący się. Jego zadaniem jest wyciąganie wniosków z akcji podejmowanych przez trenowanego agenta, ocenianie, w jakim stopniu przybliżają one zdobycie nagrody, a także takie przypisywanie wag do poszczególnych połączeń sieci neuronowej, by znalazła ona optymalne działanie.
Najlepiej wybić piłkę na aut
Google Research Football jest środowiskiem i służy do testowania algorytmów uczących. W porównaniu do innych dostępnych obecnie środowisk ma kilka zalet, które mogą przesądzić o tym, że stanie się nowym benchmarkiem w dziedzinie reinforced learningu. GRF opiera się na wolnej licencji, jest otwarty na modyfikacje i ma relatywnie niskie wymagania sprzętowe – a to wszystko pozwala na wykorzystywanie go przez badaczy, którzy nie dysponują wielkimi zasobami obliczeniowymi. Dotychczas rozwój zaawansowanej sztucznej inteligencji był domeną instytucji dysponujących większymi budżetami. Środowisko to pozwala także na trenowanie wielu agentów naraz, także rywalizujących ze sobą. Dodatkowo GRF ma charakter stochastyczny, czyli zawiera w sobie elementy losowości.
Prawdziwy świat jest stochastyczny.
Google Research Football, czyli środowisko do treningu sztucznej inteligencji (źródło: Google Research)
„Zauważyliśmy, że jest potrzeba badania algorytmów w środowisku stochastycznym, bo są algorytmy, które dobrze sobie radzą w deterministycznych środowiskach. Ale prawdziwy świat jest stochastyczny” – mówi Kurach. Dodaje, że w szachach, „go”, czy grach Atari sztuczna inteligencja jest w stanie osiągać wyniki lepsze niż ludzcy gracze. W deterministycznych środowiskach łatwo jest algorytmowi odkryć najlepszą ścieżkę i z niej korzystać.
Problemem, z którym mierzy się obecnie machine learning jest tzw. sample complexity, czyli liczba prób, które algorytm musi wykonać, by nauczyć się, jak działać. Na przykład, wytrenowanie sieci neuronowej, aby była w stanie pokonać komputerowego przeciwnika zaprogramowanego na średni poziom trudności, wymagało – zależnie od zastosowanego algorytmu uczącego – wykonania nawet 500 mln kroków, czyli rozegrania blisko 170 tys. meczów. Nie jest to tak wielki problem przy grach wideo – standardowy komputer mógłby w tym środowisku wykonać ok. 140 mln kroków dziennie, a przyspieszenie lub zwiększenie skali procesu wymaga użycia kilku procesorów więcej. Jednak trenowanie w ten sposób sztucznej inteligencji na potrzeby robotyki jest już niewykonalne – nikt nie będzie czekał, aż robot przewróci się pół miliarda razy zanim nauczy się chodzić.
Nikt nie będzie czekał, aż robot przewróci się pół miliarda razy zanim nauczy się chodzić.
„My algorytmowi nie mówimy nic. Ma do wyboru pewien zakres akcji, ale nie wie, jakiego efektu się spodziewać. Algorytm widzi stan układu, czyli to, co wyświetla się na ekranie, zestaw pikseli, lub w uproszczonej wersji – położenie piłkarzy i piłki. Algorytm widzi serię liczb, ale nie wie, co one znaczą. Ma zasób akcji, które mogą zmienić te liczby. I jak strzeli gola, to dostaje nagrodę, a jak straci gola – dostaje karę” – tłumaczy Kurach.
Początkowo wagi przypisane połączeniom w sieci neuronowej są losowe, a zatem agent również podejmuje przypadkowe działania. Dopiero po jakimś czasie zaczyna rozumieć, że niektóre zachowania zbliżają go do uzyskania nagrody, a niektóre – nie.
„To pokazuje, jak ważny w reinforced learning jest sposób ustalenia nagrody. Rozważaliśmy prosty scenariusz – sam na sam z bramkarzem. Intuicyjnie, człowiek w takiej sytuacji biegłby z piłką w stronę bramki i próbował pokonać bramkarza strzałem. I w większości przypadków by to działało. Ale nasze środowisko jest losowe, więc nie każdy strzał kończy się golem – piłka może minąć bramkę, uderzenie może obronić bramkarz. To, co wymyśliła sztuczna inteligencja, to… wybicie piłki na aut przez napastnika. Reguły rządzące środowiskiem wymuszały w takiej sytuacji, by drużyna przeciwna wykonała wrzut z autu, a że jedynym jej przedstawicielem w tym scenariuszu jest bramkarz, to bramka zostawała pusta” – opowiada programista.
Eksploracja i zamrożenie
Cykl życia sztucznej inteligencji dzieli się na fazę trenowania i fazę wykonania. W pierwszej, sieć neuronowa się uczy, szukając najlepszej drogi ku maksymalizacji nagrody – wówczas wagi, według których podejmowane są decyzje zmieniają się. Im wyższa waga, tym częściej agent zachowa się w taki sposób w kolejnych próbach. Ale póki trwa trening, póty trwa eksploracja. A to oznacza, że nawet jeśli algorytm nauczy się po milionie skutecznych prób, że będąc przed pustą bramką najlepiej strzelić w sam jej środek, to „na wszelki wypadek” za milion pierwszym razem może „przetestować”, co by było, gdyby jednak wybił ją w trybuny.
Koniec treningu oznacza zaś „zamrożenie” sieci neuronowej i wypracowanych przez nią wag, a więc wzorców zachowania. Może być teraz stosowana, jednak już dalej się nie uczy. I ponownie pojawia się tu problem z zastosowaniem tej technologii w urządzeniach takich jak np. samochody autonomiczne. Nie można pozwolić sobie, by algorytmy uczyły się jeżdżąc po prawdziwych ulicach, a raz na jakiś czas, na próbę, wjeżdżały w drzewa. Dlatego trenowanie przeprowadza się zazwyczaj w symulatorach. Te jednak nie są doskonałe.
„Zacznijmy od tego, że nikt nie pozwoli samochodom jeździć bez żadnej kontroli. Programy sterujące takimi pojazdami są to zazwyczaj produkty inżynierskie, łączące wiele systemów – są to miksy systemów zaprojektowanych przez specjalistów z systemami uczącymi się” – mówi Kurach. „Na przykład roboty produkowane przez firmę Boston Dynamics początkowo nie miały w sobie prawie wcale uczenia maszynowego, i opierały się głównie na algorytmach probabilistycznych i klasycznej teorii kontroli. Z jednej strony to podejście, które zapewnia, że wiemy wszystko o tym robocie, ale z drugiej – ciężko wymyślić i zaprogramować wszystkie możliwości” – dodaje.
Dlatego tak ważne jest, by opracować algorytmy uczące się, które będą potrzebowały znacznie mniej prób, by skutecznie wytrenować sieć neuronową. I w osiągnięciu tego celu ma pomagać środowisko stworzone pod kierownictwem polskiego programisty.
Najlepszy chirurg na świecie
Jego zdaniem machine learning to wielka nadzieja dla świata. Sztuczna inteligencja może zastąpić nas w prostych powtarzalnych pracach – dla także wspomóc ludzi w tych zaawansowanych, np. w chirurgii.
„Teoretycznie moglibyśmy mieć najlepszego chirurga na świecie, który, wspomagany przez sztuczną inteligencję, będzie mógł wykonywać cięcia z niezwykłą dokładnością. I do wytrenowania go nie potrzeba, by specjaliści pracowali nad poszczególnymi procedurami. Hipotetycznie wystarczyłoby, by algorytm mógł uczyć się obserwując” – przewiduje Kurach.
Przeszkodą na tej drodze jest jednak długość procesu uczenia się. A nawet dobrze wytrenowana sieć działa na zasadzie reakcji na bodźce, nie przewidując, co się może za chwilę wydarzyć. Co więcej, nie zdaje sobie ona sprawy, jakie konsekwencje jej działanie wywoła. Jeśli kierowany przez sztuczną inteligencję piłkarz podaje piłkę do napastnika, to nie robi tego, bo wie, że znajduje się on na lepszej pozycji do strzału, tylko dlatego, że taka akcja ma przypisaną najwyższą wagę dla takiego stanu. O filozofię i psychologię ociera się w takiej sytuacji pytanie, czy gdy na prawdziwym boisku Kuba Błaszczykowski podaje do zauważonego kątem oka Roberta Lewandowskiego, to zdaje sobie sprawę z tego, co robi, czy przewiduje konsekwencje swojego działania, czy też oddając kontrolę nad swoim zachowaniem wytrenowanemu przez lata instynktowi, również polega na zapisanych w podświadomości schematach.
„W prostych środowiskach, jak np. szachy – mamy model określonego świata tej gry. Algorytm umie przewidzieć stan tego świata po wykonaniu akcji. I w takich środowiskach możliwe jest planowanie. Natomiast w przypadkach, w których model jest dużo bardziej skomplikowany, algorytmy nie przewidują, tylko reagują. Ale jest to obecnie bardzo aktywna dziedzina badań – jak budować model świata i planowanie działań. Wierzymy, że jak się to uda z sukcesem zrobić, to będzie można wykorzystać raz wyuczony model i zastosować go w innych algorytmach i symulacjach” – tłumaczy Kurach.
Obecnie bowiem każdy proces uczenia się zaczyna się od zera, każda sieć neuronowa to tabula rasa. Sztuczna inteligencja uczy się na własnych doświadczeniach, ale nie jest w stanie przekazać tej wiedzy do kolejnych treningów innych agentów.
Rozwój sztucznej inteligencji, uczenia maszynowego stoi przed wieloma problemami do rozwiązania. Jak przyspieszyć proces treningu, jak nauczyć algorytmy przewidywania zdarzeń w świecie, którym rządzi przypadek?
„Jeśli chcemy tworzyć algorytmy, które mają zastosowanie w rzeczywistości, to musimy je trenować w środowiskach, które są stochastyczne” – konkluduje programista Google Brain.
Ekspansja fintechów nie pozostaje bez wpływy na działalność banków, ich przychody i politykę ryzyka. Funkcjonowanie nowych graczy jest wyzwaniem, ale przynosi także efekty pozytywne dla sektora bankowego.
Stany Zjednoczone są jedynym militarnym supermocarstwem świata: wydają na siły zbrojne więcej niż dziesięć kolejnych krajów łącznie. Chiny natomiast stały się jedynym na świecie supermocarstwem w przetwórstwie przemysłowym (manufacturing). Produkcja Chin przewyższa produkcję dziewięciu następnych krajów na liście razem wziętych.
Po dwóch latach deficytu, Polska odnotowała w 2023 r. dodatnie saldo w obrotach handlowych. Poprawa salda nastąpiła we wszystkich głównych kategoriach towarów, a najsilniej w paliwach. Głównym czynnikiem tych tendencji były wyraźnie lepsze warunki cenowe w polskim handlu zagranicznym.
Produkcja ropy na Alasce znalazła się na poziomie najniższym od 45 lat. Ludzie wyjeżdżają stamtąd. Stan ma problemy budżetowe, które będzie chciał załatać m.in. uruchomieniem sprzedaży kredytów węglowych.
Portugalia nie wykorzystała możliwości, jakie dawało wstąpienie do Unii Europejskiej, a wręcz cofnęła się w rozwoju gospodarczym w minionych prawie dwudziestu pięciu latach. W niniejszym artykule autor przekonuje, że ten rozczarowujący rezultat wynika w dużej mierze z polityki ukierunkowanej na bieżącą konsumpcję zamiast na rozwój oparty na sektorze prywatnym.
Ceny konsumpcyjne rosły w Stanach Zjednoczonych w tempie 3,5 proc., co stawia pod dużym znakiem zapytania perspektywę cięcia stóp procentowych za Oceanem. Odczyt inflacji CPI za marzec 2024 r. w USA był nieznacznie wyższy od rynkowego konsensusu i postawił Komitet Otwartego Rynku w niełatwym położeniu.
Specjalne wydanie „Obserwatora Finansowego”, poświęcone jest najważniejszym reformom w historii polskiej bankowości. Powodem jest okrągła rocznica stu lat od kluczowych dla dzisiejszych sukcesów Polski wydarzeń. Jaką drogę przeszedł polski złoty od powstania, do chwili obecnej? Na czym opiera się wiarygodność i zaufanie do Narodowego Banku Polskiego? Jakie były wyzwania i alternatywy po drodze? O tym wszystkim można przeczytać w wydaniu kwartalnika.
Najnowsze wydanie „Obserwatora Finansowego” ukazuje nam wizje przyszłości bliskiej i dalekiej. W tym numerze, najlepsi eksperci postarają się odpowiedzieć na kilka kluczowych pytań, dotyczących sztucznej inteligencji i tego jak generatywna AI wpłynie na bankowość, edukację oraz inne dziedziny naszego życia.
Nieefektywność nadzoru prowadzi do występowania nieprawidłowości i nadużyć na rynku funduszy inwestycyjnych w Polsce – taką sensacyjną tezę stawiają autorzy monografii „Nieprawidłowości i nadużycia na rynku funduszy inwestycyjnych”.
W zasadzie przesądzone zostało wprowadzenie cyfrowej waluty w ujęciu globalnym. Pozostaje natomiast pytanie, jak długo państwa posiadające własne banki centralne, zdolne do kształtowania mniej lub bardziej polityki monetarnej, będą mogły opóźniać wprowadzenie cyfrowego pieniądza banków centralnych (CBDC – Central Bank Digital Currency) i jak długo gotówka pozostanie w niektórych państwach alternatywnym środkiem płatniczym, zabezpieczając konkurencyjność obrotu gospodarczego i wolność wyboru?
Sztuczna inteligencja powoli zmienia sposób działania banków i instytucji finansowych. Pomaga im zredukować ciężar biurokracji, ale także podejmować szybsze decyzje oraz utrzymywać efektywny kontakt z klientami. A będzie jeszcze lepiej. W perspektywie czeka kilkunastoprocentowy wzrost EBITDA.
Współczesne problemy prawne Unii Europejskiej, sztuczna inteligencja w bankowości oraz polityka pieniężna były tematami grudniowego zjazdu na podyplomowych studiach MBA organizowanych w ramach drugiej edycji projektu „Akademia NBP”.
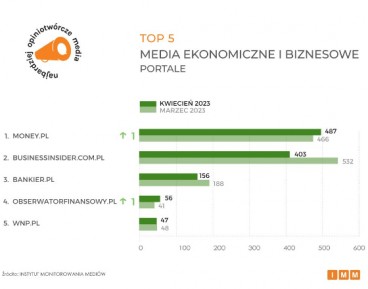
Portal ekonomiczny NBP „Obserwator Finansowy” ponownie znalazł się w czołówce najbardziej opiniotwórczych mediów w kategorii „Media ekonomiczne i biznesowe”, wyprzedzając m.in. „Parkiet”. Wzrost cytowalności treści publikowanych na łamach serwisu wzrósł w kwietniu w odniesieniu do marca 2023 r. o 37 proc.
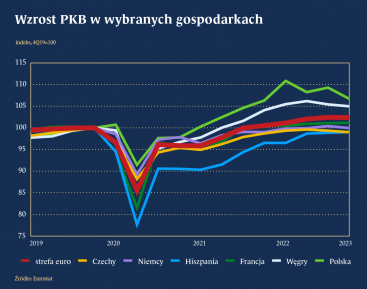
Sytuacja gospodarcza w Polsce na tle innych krajów przedstawia się korzystnie. Warto zauważyć, że w szybkim tempie nadrabiamy dystans dzielący Polskę od poziomu życia w wybranych państwach europejskich. W ciągu ostatnich czterech lat dynamika wzrostu PKB plasowała Polskę powyżej innych krajów europejskich, zarówno strefy euro, w tym Niemiec i Francji, jak i krajów Unii Europejskiej z własną walutą, np. Czech.
Większość polskich przedsiębiorców odczuła skutki wojny w Ukrainie, choć jej wpływ oceniają w zróżnicowany sposób – wynika z badania przeprowadzonego przez Polski Instytut Ekonomiczny.
W styczniu 2020 roku Wielka Brytania formalnie opuściła Unię Europejską. Oczekiwane korzyści z brexitu, poza odzyskaniem suwerenności w zakresie kształtowania prawa i zewnętrznych relacji gospodarczych, jednak się nie zmaterializowały. Widoczny jest natomiast spadek wydajności i konkurencyjności brytyjskiej gospodarki, co wpływa także na kondycję rynku pracy.