Osiągi współczesnych komputerów i ogrom danych, jakimi dysponujemy budzą nadzieję, że uda się zapanować nad światem w którym żyjemy – lepiej przewidywać przyszłość, stworzyć nowe, potrzebne usługi. Ale często jest tak, że im więcej danych mamy, tym mniej z nich rozumiemy.
Nicolas Nassim Taleb ostrzega: wszelkiego rodzaju dane w dużych ilościach są szkodliwe (CC BY-SA Agathe B)
Kiedy pojawiły się pierwsze komputery, wielu ludzi, w tym znanych ekonomistów liczyło, że teraz będzie można rozwiązać wielkie problemy gospodarcze. Centralni planiści mieli nadzieję, że dzięki ich wykorzystaniu znikną niedobory. Potem przyszła szara rzeczywistość i okazało się że nawet najbardziej zaawansowany komputer nie jest w stanie modelować bardzo złożonej rzeczywistości, w jakiej żyjemy. Najprostszym modelem galaktyki jest galaktyka. Moda na cybernetykę przyszła i minęła.
Dziś wraca, bo dysponujemy ogromną siłą obliczeniową i, dzięki internetowi, ogromną ilością danych. Nasuwa się tylko pytanie czy można mieć jakiś pożytek z ich analizy. Można mieć do co tego poważne wątpliwości.
Nicolas Nassim Taleb, autor bardzo znanej książki „The Black Swan: The Impact of the Highly Improbable” twierdzi, że im więcej zmiennych się analizuje, tym nadproporcjonalnie więcej fałszywych korelacji się znajduje.
Szum i sygnał
Żeby zrozumieć dlaczego tak się dzieje, potrzeba dokonać rozróżnienia napływających danych. Szum to przypadkowe, nic nie znaczące dane, sygnał to dane, które niosą istotną, pożyteczną informację. Posłużę się jeszcze raz wykresem z książki Taleba, która ma się ukazać na jesieni.
Mając dostęp do dużej ilości danych można łatwo utonąć w szumie.
Taleb tłumaczy:
Jeśli chcesz przyspieszyć czyjąś śmierć, daj mu osobistego lekarza.
Dostęp do danych, zwiększa liczbę podejmowanych działań – w każdej dziedzinie. Rory Sutherland powiedział mi, że ludzie, którzy mają osobistego lekarza są szczególnie narażeni, bo mogą ucierpieć z powodu niepotrzebnie podejmowanych zabiegów. Lekarze chcą pokazać, że zasługują na swoje pensje i udowodnić sobie, że mają etykę pracy, a „nic nierobienie” nie spełnia tych warunków. Kiedy piszę te słowa odbywa się proces osobistego lekarza zmarłego piosenkarza Michaela Jacksona oskarżonego o doprowadzenie do jego śmierci przez zbyt intensywne kuracje. Prawdopodobnie to samo przytrafiło się Elvisowi Presleyowi.
Podobnie jest w korporacjach i w instytucjach publicznych wyposażonych w duże departamenty statystyczne. Otrzymują one mnóstwo „aktualnych” danych i często traktują szumy jako sygnał. Greenspan na przykład obserwował sprzedaż odkurzaczy w Cleveland, „żeby mieć dokładny ogląd, w jakim kierunku idzie gospodarka”, przez co oczywiście doprowadził nas do chaosu.
W biznesie i polityce gospodarczej, obfitość danych ma poważne efekty uboczne – im więcej danych tym więcej fałszywych korelacji wykrywany. Dane są toksyczne w dużych, nawet umiarkowanych ilościach.
Im częściej patrzy się na dane, tym więcej szumu się dostaje (zamiast cennej części danych zwanych sygnałem). Powstaje zamieszanie, które nie wynika z ograniczeń psychologicznych badacza, ale z samej natury danych. Powiedzmy, że patrzymy na jakiś roczny wskaźnik – zmiany ceny akacji, sprzedaży nawozów w fabryce twojego teścia czy inflację we Władywostoku. Załóżmy dalej, że obserwowana dana ma współczynnik sygnału do szumu na poziomie 1 (połowa szum, połowa sygnał), co oznacza, że połowa wzrostów i spadków jest rzeczywista, a druga połowa jest przypadkowa. Taki wynik otrzymujemy analizując dane roczne. Jeśli analizujemy dane dzienne, dostaniemy 95 proc. szumów i 5 proc. sygnału. A gdy ktoś obserwuje jak dane zmieniają się z godziny na godzinę, dostaje 99,5 proc. szumu i 0,5 proc. sygnału. Dlatego każdy kto bacznie obserwuje ceny instrumentów i nasłuchuje newsów jest frajerem.
Prawdziwy obraz zjawiska (sygnał) widać dopiero z dłuższej perspektywy. W tym zadaniu komputery na razie nie są w stanie zastąpić ludzi.
Dlaczego nie? Przecież można komputerowi wydać polecenie, aby analizował długoterminowe trendy.
Problem polega na tym, że komputer sam nie jest w stanie określić co to jest długoterminowy trend, czy jest to kwartał, czy rok, dekada, czy stulecie. W ostatecznej instancji to użytkownik decyduje jak zdefiniować problem i to właśnie determinuje jaki będzie wynik. Trzeba wiedzieć jakie pytanie zadać komputerowi.
Powiedzmy, że Biuro Prasowe Białego Domu chce wiedzieć, co elektorat myśli o posunięciach prezydenta Obamy. Zapada więc decyzja, żeby analizować wpisy na tweeterze. Komputer z łatwością odfiltruje wszystkie wpisy w których pojawia się słowo „Obama”. Ale jak stwierdzić czy dana wypowiedź jest dla krytyczna czy pozytywna? Dlaczego jest krytyczna lub pozytywna? Komputery w chwili obecnej nadal nie rozumieją języka naturalnego, jakim posługują się ludzie (na marginesie warto dodać, że jest to znane kryterium czy mamy już do czynienia ze sztuczną inteligencją. Tzw. test Turinga polega na tym czy użytkownik przez komunikator jest w stanie odróżnić czy jego rozmówcą jest żywy człowiek czy maszyna. Jeśli nie jest w stanie tego rozróżnić, mamy do czynienia ze sztuczną inteligencją). Nie mają poczucia humoru, nie wiedzą co to ironia, co ma fundamentalne znaczenie dla ludzkiej komunikacji.
To oczywiście nie znaczy, że systemy komputerowe analizujące ogromne zbiory danych (Big Data) nie są użyteczne. Rozpoznanie piosenki po jej kilkusekundowym fragmencie jest możliwe jedynie, gdy dysponuje się ogromną bazą materiału i zapewne jest to funkcjonalność, która spodoba się wielu użytkownikom. Wątpliwym pozostaje natomiast to czy Big Data pomoże zrozumieć i radzić sobie ze złożonymi zjawiskami, w szczególności tymi związanymi z ludzkimi zachowaniami np. na giełdzie. Zyski z tych czasochłonnych analiz mogą okazać się pozorne, w przeciwieństwie do bardzo realnych strat, gdy jeszcze bardziej zaostrzy się deficyt ludzi, którzy wśród drzew potrafią dostrzec las.
Nicolas Nassim Taleb ostrzega: wszelkiego rodzaju dane w dużych ilościach są szkodliwe (CC BY-SA Agathe B)
Ekspansja fintechów nie pozostaje bez wpływy na działalność banków, ich przychody i politykę ryzyka. Funkcjonowanie nowych graczy jest wyzwaniem, ale przynosi także efekty pozytywne dla sektora bankowego.
Stany Zjednoczone są jedynym militarnym supermocarstwem świata: wydają na siły zbrojne więcej niż dziesięć kolejnych krajów łącznie. Chiny natomiast stały się jedynym na świecie supermocarstwem w przetwórstwie przemysłowym (manufacturing). Produkcja Chin przewyższa produkcję dziewięciu następnych krajów na liście razem wziętych.
Po dwóch latach deficytu, Polska odnotowała w 2023 r. dodatnie saldo w obrotach handlowych. Poprawa salda nastąpiła we wszystkich głównych kategoriach towarów, a najsilniej w paliwach. Głównym czynnikiem tych tendencji były wyraźnie lepsze warunki cenowe w polskim handlu zagranicznym.
Produkcja ropy na Alasce znalazła się na poziomie najniższym od 45 lat. Ludzie wyjeżdżają stamtąd. Stan ma problemy budżetowe, które będzie chciał załatać m.in. uruchomieniem sprzedaży kredytów węglowych.
Portugalia nie wykorzystała możliwości, jakie dawało wstąpienie do Unii Europejskiej, a wręcz cofnęła się w rozwoju gospodarczym w minionych prawie dwudziestu pięciu latach. W niniejszym artykule autor przekonuje, że ten rozczarowujący rezultat wynika w dużej mierze z polityki ukierunkowanej na bieżącą konsumpcję zamiast na rozwój oparty na sektorze prywatnym.
Ceny konsumpcyjne rosły w Stanach Zjednoczonych w tempie 3,5 proc., co stawia pod dużym znakiem zapytania perspektywę cięcia stóp procentowych za Oceanem. Odczyt inflacji CPI za marzec 2024 r. w USA był nieznacznie wyższy od rynkowego konsensusu i postawił Komitet Otwartego Rynku w niełatwym położeniu.
Specjalne wydanie „Obserwatora Finansowego”, poświęcone jest najważniejszym reformom w historii polskiej bankowości. Powodem jest okrągła rocznica stu lat od kluczowych dla dzisiejszych sukcesów Polski wydarzeń. Jaką drogę przeszedł polski złoty od powstania, do chwili obecnej? Na czym opiera się wiarygodność i zaufanie do Narodowego Banku Polskiego? Jakie były wyzwania i alternatywy po drodze? O tym wszystkim można przeczytać w wydaniu kwartalnika.
Najnowsze wydanie „Obserwatora Finansowego” ukazuje nam wizje przyszłości bliskiej i dalekiej. W tym numerze, najlepsi eksperci postarają się odpowiedzieć na kilka kluczowych pytań, dotyczących sztucznej inteligencji i tego jak generatywna AI wpłynie na bankowość, edukację oraz inne dziedziny naszego życia.
Nieefektywność nadzoru prowadzi do występowania nieprawidłowości i nadużyć na rynku funduszy inwestycyjnych w Polsce – taką sensacyjną tezę stawiają autorzy monografii „Nieprawidłowości i nadużycia na rynku funduszy inwestycyjnych”.
W zasadzie przesądzone zostało wprowadzenie cyfrowej waluty w ujęciu globalnym. Pozostaje natomiast pytanie, jak długo państwa posiadające własne banki centralne, zdolne do kształtowania mniej lub bardziej polityki monetarnej, będą mogły opóźniać wprowadzenie cyfrowego pieniądza banków centralnych (CBDC – Central Bank Digital Currency) i jak długo gotówka pozostanie w niektórych państwach alternatywnym środkiem płatniczym, zabezpieczając konkurencyjność obrotu gospodarczego i wolność wyboru?
Budowa Centralnego Portu Komunikacyjnego wzmocniłaby znacznie pozycję Polski w europejskiej gospodarce – stwierdził w rozmowie z „Obserwatorem Finansowym" dr Andreas Wittmer, dyrektor zarządzający Centrum Badań Lotniczych na Uniwersytecie w St. Gallen.
Współczesne problemy prawne Unii Europejskiej, sztuczna inteligencja w bankowości oraz polityka pieniężna były tematami grudniowego zjazdu na podyplomowych studiach MBA organizowanych w ramach drugiej edycji projektu „Akademia NBP”.
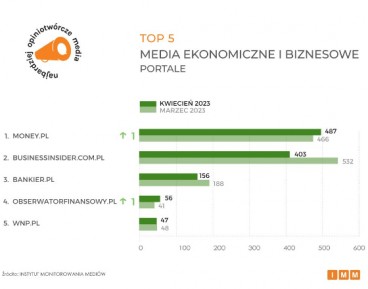
Portal ekonomiczny NBP „Obserwator Finansowy” ponownie znalazł się w czołówce najbardziej opiniotwórczych mediów w kategorii „Media ekonomiczne i biznesowe”, wyprzedzając m.in. „Parkiet”. Wzrost cytowalności treści publikowanych na łamach serwisu wzrósł w kwietniu w odniesieniu do marca 2023 r. o 37 proc.
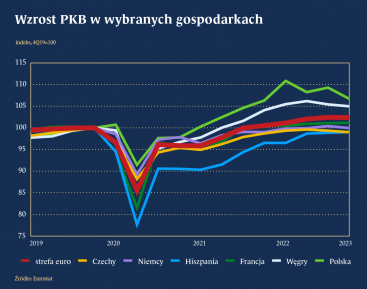
Sytuacja gospodarcza w Polsce na tle innych krajów przedstawia się korzystnie. Warto zauważyć, że w szybkim tempie nadrabiamy dystans dzielący Polskę od poziomu życia w wybranych państwach europejskich. W ciągu ostatnich czterech lat dynamika wzrostu PKB plasowała Polskę powyżej innych krajów europejskich, zarówno strefy euro, w tym Niemiec i Francji, jak i krajów Unii Europejskiej z własną walutą, np. Czech.
Większość polskich przedsiębiorców odczuła skutki wojny w Ukrainie, choć jej wpływ oceniają w zróżnicowany sposób – wynika z badania przeprowadzonego przez Polski Instytut Ekonomiczny.
W styczniu 2020 roku Wielka Brytania formalnie opuściła Unię Europejską. Oczekiwane korzyści z brexitu, poza odzyskaniem suwerenności w zakresie kształtowania prawa i zewnętrznych relacji gospodarczych, jednak się nie zmaterializowały. Widoczny jest natomiast spadek wydajności i konkurencyjności brytyjskiej gospodarki, co wpływa także na kondycję rynku pracy.