Na globalnym szczycie poświęconym bezpieczeństwu sztucznej inteligencji, wiceprezydent USA Kamala Harris stwierdziła, że „to Ameryka może katalizować globalne działania i budować globalny konsensus w sposób, w jaki żaden inny kraj nie jest w stanie tego zrobić”. Niniejszy artykuł dowodzi, że proponując ambitną ustawę o sztucznej inteligencji to UE wysuwa się na czoło, jeśli chodzi o przyjmowanie kompleksowych i szczegółowych przepisów. Ustawa ta zakłada podejście oparte na ryzyku, które ma na celu zapobieganie szkodliwym skutkom ex ante. Autorzy argumentują, że zamiast szczegółowych deklaracji ryzyka, właściwsze byłoby przyjęcie zasad przypisania odpowiedzialności podjętych na podstawie dokładnych informacji (ex post), jako że zostawiają one więcej miejsca dla innowacji typu open source i zachęcają do inwestowania w wysokiej jakości dane wejściowe do modeli.
Podczas szczytu w sprawie bezpieczeństwa sztucznej inteligencji w Bletchley Park (siedzibie brytyjskich kryptografów w czasie II wojny światowej), który odbył się 1–2 listopada 2023 r., wiceprezydent USA Kamala Harris powiedziała dobitnie: „Postawmy sprawę jasno: jeśli chodzi o sztuczną inteligencję, Ameryka jest światowym liderem. To amerykańskie firmy przodują na świecie w innowacjach AI. To Ameryka może katalizować globalne działania i budować globalny konsensus w sposób, w jaki żaden inny kraj nie jest w stanie tego zrobić” (Biały Dom 2023c).
Jak ma się to stwierdzenie do unijnych ambicji stanowienia globalnych zasad regulujących kwestię sztucznej inteligencji? W niniejszym artykule, w oparciu o naszą najnowszą pracę (Kretschmer i in. 2023) wyjaśniamy złożoną „hierarchię ryzyka”, która stanowi fundament ustawy o sztucznej inteligencji (Komisja Europejska 2023). Kontrastuje ona z podejściem Stanów Zjednoczonych akcentujących kwestie „zagrożenia dla bezpieczeństwa narodowego”, które są obszarem, na którym władze wykonawcze szczebla federalnego mogą wywierać naciski na firmy zajmujące się sztuczną inteligencją (Federal Register 2023). Wskazujemy na wady podejścia UE, które wymaga kompleksowej oceny ryzyka (ex ante) na poziomie rozwoju technologii. Korzystając z analizy ekonomicznej, rozróżniamy egzogeniczne i endogeniczne typy potencjalnych szkód związanych ze sztuczną inteligencją, wynikające z danych wejściowych. Sugerujemy, że z punktu widzenia promowania innowacji, zasady przypisywania odpowiedzialności (ex post) mogą tworzyć odpowiednie zachęty do poprawy jakości danych i bezpieczeństwa sztucznej inteligencji.
Konkurencja regulacyjna
Istnieje globalne oczekiwanie i atmosfera ekscytacji wśród inwestorów, że sztuczna inteligencja zmieni sposób naszego życia i zaoferuje potencjalnie ogromne korzyści w edukacji, energetyce, opiece zdrowotnej, produkcji, transporcie. Technologia ta nadal rozwija się szybko wraz z postępami w głębokim uczeniu się ze wzmocnieniem (RL) (Kaufmann i in. 2023) oraz implementacją i udoskonalaniem modeli fundamentalnych (Moor i in. 2023) w różnych kontekstach wykraczających poza szkoleniowe zbiory danych.
Pojawienie się sztucznej inteligencji skierowanej do konsumentów, czego przykładem jest błyskawiczny rozwój ChatGPT (dużego generatywnego modelu językowego uruchomionego przez OpenAI.com w listopadzie 2022 r.), sprawiło, że działanie modeli uczenia maszynowego stało się bardziej widoczne i wzbudziło poważne obawy co do polityki bezpieczeństwa, tendencyjności wyników, ochrony danych osobowych, praw własności intelektualnej, struktury branżowej, a przede wszystkim nieprzejrzystości technologii, tj. braku możliwości wyjaśnienia i interpretacji (CREATe 2023) wyników.
W tym kontekście duże bloki gospodarcze próbują identyfikować i łagodzić zagrożenia, kształtować globalny program polityczny i konkurować o ustanowienie porządku regulacyjnego. Deklaracja przyjęta na szczycie w sprawie bezpieczeństwa sztucznej inteligencji zawiera godne pochwały zobowiązania do „zintensyfikowania i utrzymania naszej współpracy” (Rząd Wielkiej Brytanii 2023). Działając wyprzedzająco w stosunku do obrad szczytu, administracja USA wydała rozporządzenie wykonawcze w sprawie „bezpiecznej i godnej zaufania sztucznej inteligencji” (Biały Dom 2023b), opierając się na dobrowolnych zobowiązaniach (Biały Dom 2023a) uzyskanych w czerwcu 2023 r. od siedmiu kluczowych amerykańskich firm (Amazon, Anthropic, Google, Inflection, Meta, Microsoft i OpenAI). Chiny natomiast przyjęły już „Środki tymczasowe dotyczące zarządzania usługami sztucznej inteligencji generatywnej” (Chińska Administracja Cyberprzestrzeni 2023), które weszły w życie 15 sierpnia 2023 r.
To UE jest jednak najbardziej zaawansowana w przyjmowaniu kompleksowego i szczegółowego prawodawstwa, Ustawa o AI ma wejść w życie przed wyborami do Parlamentu Europejskiego w czerwcu 2024 r.
Nowe przepisy UE są złożone i będą miały wpływ na politykę naukową i technologiczną na całym świecie, nawet jeśli inne jurysdykcje zdecydują się pójść inną ścieżką. Ustawy o AI nie może obejść nikt, kto „wprowadza na rynek, oddaje do użytku i użytkuje” systemy sztucznej inteligencji w UE. Nierealistyczne wymogi ex ante dotyczące oceny ryzyka na etapie rozwoju mogą jednakże również utrudniać innowacje i przesuwać inwestycje do mniej restrykcyjnych jurysdykcji.
Unijna klasyfikacja wszystkich systemów sztucznej inteligencji oparta na ryzyku
UE postrzega sztuczną inteligencję jako technologię potencjalnie wysokiego ryzyka, która wymaga interwencji, jeszcze zanim będzie można zbadać jej zastosowania i przydatność na dużą skalę. Zapożyczając koncepcje z przepisów dotyczących bezpieczeństwa produktów, ustawa o sztucznej inteligencji ustanowi obowiązki operatorów sztucznej inteligencji proporcjonalnie do powagi i zakresu szkód, jakie mogą powodować systemy AI. Rozporządzenie opiera się na hierarchii ryzyka.
Po pierwsze, ustawa o sztucznej inteligencji wyróżnia pewne „praktyki” AI, które będą z góry zabronione. Praktyki te obejmują (1) systemy sztucznej inteligencji wykorzystujące techniki podprogowe poza świadomością danej osoby w celu istotnego zniekształcenia jej zachowania; (2) systemy sztucznej inteligencji, które wykorzystują słabości określonej grupy osób ze względu na ich wiek, niepełnosprawność fizyczną lub umysłową; (3) nieuzasadnione lub nieproporcjonalne systemy punktacji społecznej stosowane przez władze publiczne oraz (4) wykorzystanie zdalnych systemów identyfikacji biometrycznej „w czasie rzeczywistym” w przestrzeni publicznej w celu egzekwowania prawa, chyba że jest to absolutnie niezbędne, a i wówczas jedynie w takim właśnie niezbędnym zakresie.
Po drugie, systemy AI wysokiego ryzyka podlegają kompleksowym zobowiązaniom w zakresie zarządzania ryzykiem, z uwzględnieniem „powszechnie uznanego stanu wiedzy” (art. 9 ust. 3) przez cały cykl ich życia. Dostawcy systemów AI wysokiego ryzyka muszą przejść procedurę oceny zgodności i zarejestrować się w unijnej bazie danych AI przed wejściem na rynek. Sztuczna inteligencja wysokiego ryzyka obejmuje systemy, które są związanymi z bezpieczeństwem elementami produktów lub systemów, lub które same są produktami lub systemami podlegającymi istniejącym sektorowym przepisom bezpieczeństwa (np. maszyny, urządzenia medyczne lub zabawki). Ponadto za AI wysokiego ryzyka uznaje się systemy, które mają być wykorzystywane w obszarach krytycznych, w tym w identyfikacji biometrycznej i kategoryzacji osób fizycznych, zarządzaniu i obsłudze infrastruktury krytycznej, edukacji, zatrudnieniu, dostępie do podstawowych usług prywatnych i publicznych, egzekwowaniu prawa i procesach demokratycznych.
W odpowiedzi na szał związany z ChatGPT, autorzy projektu dodali dodatkowo dwie inne kategorie AI, a mianowicie „sztuczną inteligencję ogólnego przeznaczenia” (GPAI) i modele bazowe (Hacker i in. 2023). GPAI definiuje się jako system sztucznej inteligencji przeznaczony przez dostawcę do wykonywania funkcji ogólnego zastosowania, takich jak rozpoznawanie obrazu i mowy, generowanie audio i wideo, wykrywanie wzorców, odpowiadanie na pytania, tłumaczenie i inne, a zatem może być używany w wielu kontekstach i może być zintegrowany z wieloma innymi systemami sztucznej inteligencji. Sztuczna inteligencja ogólnego przeznaczenia, która „może” być wykorzystywana jako AI wysokiego ryzyka lub jako element systemu AI wysokiego ryzyka, musi spełniać wymogi ustanowione dla takiej AI wysokiego ryzyka. Ma to zastosowanie niezależnie od tego, czy sztuczna inteligencja ogólnego przeznaczenia jest wprowadzana do użytku jako wstępnie wytrenowany model i czy dalsze dostrajanie modelu ma być przeprowadzane przez jej użytkownika.
Model bazowy w tekście Parlamentu Europejskiego rozumiany jest jako „model systemu sztucznej inteligencji, który jest szkolony na dużą skalę na szerokim zakresie danych, jest zaprojektowany z myślą o znajdowaniu rozwiązań o dużym stopniu ogólności i może być dostosowany do szerokiego zakresu charakterystycznych zadań”, a więc jako podzbiór sztucznej inteligencji ogólnego przeznaczenia. Nawet jeśli nie ma on zamierzonego zastosowania, dostawcy nadal muszą identyfikować, ograniczać i łagodzić „racjonalnie przewidywalne ryzyko”. Muszą złożyć dokumentację, taką jak arkusze danych, karty modeli i zrozumiałe instrukcje, które pozwolą „dostawcom AI na kolejnych etapach wdrożenia” zrozumieć model, a także przedstawić szczegółowe podsumowanie wykorzystania danych szkoleniowych zgodnie z prawem autorskim.
Problemy z jakością danych
Logika podejścia do zagadnienia z punktu widzenia bezpieczeństwa produktu polega na przechodzeniu wstecz od potencjalnego wystąpienia pewnych szkód do środków ograniczających ryzyko takiego wystąpienia. Uważamy jednak, że zastosowanie tej logiki do sztucznej inteligencji niesie ze sobą pewne niebezpieczeństwa. W przeciwieństwie do tradycyjnej technologii podstawowymi danymi wejściowymi sztucznej inteligencji są dane, które mogą być specyficzne dla kontekstów, które mogą zmieniać się w czasie lub którymi można manipulować.
Propozycja ustawy o sztucznej inteligencji określa wyraźne cele w zakresie jakości danych, takie jak to, że zbiory danych szkoleniowych, walidacyjnych i testowych „muszą być odpowiednie, reprezentatywne, wolne od błędów i kompletne” (art. 17 ust. 3). Kryteria te, same lub w połączeniu, są jednak niezgodne z podstawowymi pojęciami statystycznymi w uczeniu maszynowym i nierealistyczne. Na przykład zbiór danych można uznać za kompletny, jeśli zawiera tylko jedną cechę dla całej populacji, wszystkie cechy jednego podmiotu lub wszystkie cechy całej populacji. W terminologii uczenia maszynowego to ostatnie zostałoby nazwane prawdą podstawową. W sensie statystycznym reprezentatywność jest związana z kompletnością. Reprezentatywny zbiór danych odzwierciedla parametry (średnią, odchylenie standardowe, skośność itp.) rozkładu populacji, tj. „kompletnego” zbioru danych. Wreszcie to, czy zbiór danych jest wolny od błędów, można określić tylko wtedy, gdy dobrze rozumie się, czym jest prawda podstawowa, tj. mając dostęp do kompletnego zbioru danych lub reprezentatywnego zbioru danych.
Błędy w danych wejściowych nieskorelowane z wynikami (np. losowy odblask obiektywu w danych obrazu) stają się krytyczne w zastosowaniach, w których niedokładność jest akceptowalna tylko w wąskich granicach (np. pojazdy autonomiczne), a znacznie mniej istotne, jeśli sztuczna inteligencja stanowi system uzupełniający, zalecający pewne działania człowiekowi, który podejmuje ostateczną decyzję. Co więcej, aplikacje mają różną tolerancję na błędy typu I i II (Shafer i Zhang 2012: 341). Rozważmy kompromis między wolnością słowa a nielegalnymi treściami w systemach moderacji treści. Unikanie błędów typu I (nieusuwanie nielegalnych treści) wydaje się lepsze niż unikanie błędów typu II (usuwanie treści zgodnych z prawem). Błędy przewidywania można jednak sklasyfikować tylko wtedy, gdy prawda podstawowa jest znana przynajmniej w przybliżeniu.
Ryzyko wejściowe i zasady odpowiedzialności
Zamiast opracowywać niemożliwe do spełnienia obowiązki w zakresie jakości danych, które nie mogą działać na dużą skalę i bez obarczenia tendencyjnością, a także nakładać potencjalnie ogromne koszty dostosowania się do tych wytycznych, sugerujemy, aby ryzyko wejściowe, zwłaszcza dotyczące danych, oraz relacje między twórcami i podmiotami wdrażającymi systemy sztucznej inteligencji były rozpatrywane z punktu widzenia przypisania odpowiedzialności.
Ryzyko związane z danymi wejściowymi dzielimy na kategorie w zależności od przyczyn, które mogą pogarszać jakość danych. W niektórych zastosowaniach najbardziej odpowiedni zestaw danych może jeszcze nie istnieć lub niegdyś odpowiedni zestaw danych nie jest już aktualny, ponieważ w międzyczasie zmienił się kontekst. Wszystkie te kwestie są egzogeniczne; metody gromadzenia odpowiednich danych mogą jeszcze nie istnieć lub środowisko po prostu się zmieniło, ale podstawowe przyczyny, które sprawiają, że jakość danych jest nieoptymalna, nie wynikają z konkretnych działań poszczególnych interesariuszy. Z drugiej strony, jakość danych może ulec zmianie ze względu na strategiczne zachowanie uczestników rynku. Na przykład, nawet duży model językowy, który został przeszkolony na podstawie zasadniczo wszystkich informacji w Internecie, cierpi z powodu problemów z jakością danych. Może on działać tylko na podstawie informacji, które ktoś zdecydował się udostępnić publicznie. W wyniku takiej tendencyjności danych wejściowych system sztucznej inteligencji może generować dane wyjściowe o niewystarczającej jakości.
W celu skonstruowania zasad przypisywania odpowiedzialności analizujemy zatem jakość danych jako funkcję kwestii egzogenicznych, takich jak zimny start (niedostatecznie reprezentowane dane), dryf pojęć (gdy dane stają się nieaktualne) i niepełna dostępność danych z powodu ochrony prywatności. Na drugim biegunie jakość danych można rozumieć jako funkcję kwestii endogenicznych, takich jak np. istnienie podmiotów próbujących „oszukać system”, czy to za pomocą pozycjonowania na potrzeby sztucznej inteligencji, czy wrogich ataków, które wprowadzają stronnicze/wyselekcjonowane dane.
Przykładem jednorazowego wdrożenia może być komputerowy system wizyjny do rozpoznawania szczegółów tablic rejestracyjnych w celu zarządzania dostępem samochodów do garażu. Gdy system nauczy się, jak wykrywać tablice rejestracyjne na zdjęciach samochodów i jak odszyfrowywać znaki z tablic rejestracyjnych, nie ma potrzeby aktualizowania podstawowych zbiorów danych, ponieważ w średnim lub długim okresie nie będzie żadnych zmian w wyglądzie tablic rejestracyjnych. W przypadku ciągłego wdrażania możemy pomyśleć o systemie czatu połączonym z dużym modelem językowym. Aby taki system był naprawdę użyteczny, dane muszą być stosunkowo często aktualizowane, na przykład poprzez uwzględnianie opinii użytkowników lub dodawanie nowych danych do zestawu szkoleniowego.
Jasne zasady odpowiedzialności będą zachęcać firmy do inwestowania w wysokiej jakości dane wejściowe poprzez regularne aktualizowanie zbiorów danych lub niedostatecznie reprezentowanych podsekcji zbiorów danych pomimo potencjalnie wysokich kosztów lub poprzez inwestowanie w badania i rozwój w celu złagodzenia skutków tendencyjnych danych wejściowych. Podczas gdy UE proponuje dostosowanie swoich zasad przypisania odpowiedzialności za pomocą dwóch dyrektyw (Komisja Europejska 2022) mających na celu uzupełnienie ustawy o sztucznej inteligencji (Hacker 2023), są one raczej uzupełnieniem niż rusztowaniem instytucjonalnym zapewniającym bezpieczeństwo użytkowania sztucznej inteligencji. Zasady, które regulują kwestie odpowiedzialności, gdy coś pójdzie nie tak i określają, od kogo oczekuje się działania, prowadzenia napraw i ewentualnie ponoszenia kosztów, mogą ułatwić innowacje w domenie sztucznej inteligencji i szybką zmianę zachowań w niezmiennie trudnej domenie przewidywania ryzyka końcowego.
Zalecenia
Sugerujemy, że nałożenie zbyt dużego obciążenia na twórców technologii (w stosunku do podmiotów wdrażających) może (a) dać przewagę większym firmom, które są w stanie wziąć na siebie ryzyko prawne, oraz (b) spowolnić rozwój technologiczny w tej pionierskiej dziedzinie. Oznacza to, że rozwój technologiczny może zostać ukierunkowany na aplikacje, za które deweloper ponosi niewielką odpowiedzialność, czy to dlatego że większość ryzyka weźmie na siebie podmiot wdrażający, czy dlatego że jest ona uważana za aplikację o niskim ryzyku.
Choć dostawcy sztucznej inteligencji nie powinni mieć możliwości rutynowego unikania odpowiedzialności wobec operatorów na kolejnych etapach wdrożeniowych poprzez stosowanie klauzul umownych, takich jak „nie będziemy ponosić odpowiedzialności wobec kontrahenta w żadnej formie – czy to na podstawie umowy, z tytułu czynu niedozwolonego, zaniedbania, odpowiedzialności ścisłej, gwarancji lub w inny sposób – za jakiekolwiek szkody pośrednie, wynikowe, przypadkowe lub specjalne ani za utracone zyski”, sugerujemy jednak, że istnieją znaczne różnice między sztuczną inteligencją, która jest wdrażana jednokrotnie, a sztuczną inteligencją, która jest stale (ponownie) wdrażana i rozwijana. Ma to znaczenie dla zasad przypisania odpowiedzialności, które mogą wymagać od firm, aby – w szczególności –wiedziały, jakie były dane wejściowe dla ich sztucznej inteligencji i jak przekwalifikować lub dostosować systemy w celu zaradzenia naruszeniom obowiązujących przepisów.
Unijna ustawa o sztucznej inteligencji oferuje plan kompleksowego podejścia opartego na ryzyku, które ma na celu zapobieganie szkodliwym skutkom ex ante we wszystkich systemach sztucznej inteligencji i przed zaistnieniem incydentu. Społeczeństwa słusznie regulują ex ante technologie takie jak energia jądrowa, gdzie ryzyko związane z usterką jest niedopuszczalnie wysokie. Jako autorzy uważamy jednak, że sztuczna inteligencja jest bardziej podobna do elektryczności – jest to technologia ogólnego przeznaczenia. Wydaje się, że w porównaniu do wymogu szczegółowych deklaracji ryzyka, zasady przypisania odpowiedzialności na podstawie dokładnych informacji (ex post) zostawiają więcej miejsca dla innowacji typu open source (w których europejskie firmy są szczególnie biegłe) i zachęcają do inwestowania w wysokiej jakości dane wejściowe do modeli.
Uwaga autorów: rozumowanie przedstawione w niniejszym artykule zostało szerzej omówione w publikacji Kretschmer i in. (2023).
Martin Kretschmer, profesor prawa własności intelektualnej, Uniwersytet w Glasgow
Tobias Kretschmer, profesor strategii, technologii i organizacji, Monachijska Szkoła Zarządzania Uniwersytetu Ludwika Maksymiliana w Monachium (LMU)
Alexander Peukert, profesor prawa cywilnego i prawa handlowego, Uniwersytet Goethego we Frankfurcie
Christian Peukert, profesor nadzwyczajny w dziedzinie cyfryzacji, innowacji i własności intelektualnej, Uniwersytet w Lozannie (HEC)
Artykuł ukazał się w wersji oryginalnej na platformie VoxEU, tam też dostępne są przypisy i bibliografia.
W ciągu ostatniej dekady wykorzystanie sztucznej inteligencji w codziennych zadaniach gwałtownie wzrosło. W badaniu CfM-CEPR z maja 2023 r. poproszono członków europejskiego panelu o oszacowanie wpływu sztucznej inteligencji na globalny wzrost gospodarczy i stopy bezrobocia w krajach o wysokich dochodach w nadchodzącej dekadzie.
Ciekawe, kiedy sztuczna inteligencja (SI) wysadzi z rynku ekspertów tej dziedziny, któ-rzy podejmują próby opisywania procesów i pytań, na które jeszcze nie ma odpowiedzi – szczególnie w sytuacji, kiedy stała się ona bardzo szybko jedną z najbardziej transforma-cyjnych technologii naszych czasów, rewolucjonizując branże i zasadniczo zmieniając sposób działania przedsiębiorstw i inicjatyw biznesowych.
Artificial Intelligence, czyli sztuczna inteligencja, stała się nieodłącznym elementem naszej codzienności, chociaż wciąż dla wielu osób pozostaje pojęciem, które trudno zdefiniować. Przez ostatnie lata AI zrewolucjonizowała wiele dziedzin naszego życia, m.in. w jaki sposób są prowadzone firmy, metody komunikacji międzyludzkiej. Ponadto, wpływa ona na podejmowanie decyzji i postrzeganie otaczającego nas świata.
Historia pokazuje, że naród, który odzyskuje wolność i zdobywa panowanie na terytorium swojego państwa bagnetem żołnierza, nie zapewnia sobie tym samym zupełnej suwerenności. Dopiero odzyskanie władzy nad walutą narodową albo stworzenie tej waluty, staje się prawnym imperatywem suwerenności i fundamentem stabilnej gospodarki narodowej.
Droga energia, slowbalizacja, brak rąk do pracy, nadmierna biurokracja, wieloletnie zaniedbania inwestycyjne oraz opóźnienia technologiczne spętały potencjał rozwojowy Niemiec. Gospodarka przechodzi przez polikryzys– spowodowany wieloma czynnikami – na który nie ma prostej odpowiedzi w postaci np. pakietu koniunkturalnego lub jednej, porządnej reformy. RFN potrzebuje w istocie polireformy – dziesiątków drobnych korekt, które jednak jako całość określą na nowo równowagę między rynkiem a państwem.
W ciągu ostatnich 200 lat bankowość centralna przeszła poważną ewolucję, zmieniały się jej zadania oraz reguły polityki pieniężnej. Tekst pokazuje z tej perspektywy dwa banki centralne: Bank Polski (1828–1866) oraz Bank Polski SA (1924–1939). Akcent położono na okoliczności ich powstania oraz intencje i oczekiwania projektodawców, które zdeterminowały statutowy zakres ich uprawnień. Pokazano trudne wybory odnośnie do priorytetów i gradacji celów, przed jakimi stawiała je rzeczywistość gospodarcza. Okoliczności te skłaniały do pytań o właściwe cele i zasady funkcjonowania banków centralnych, tworzyły przestrzeń dla ścierania się koncepcji swoistego bankowego wariabilizmu i statyzmu.
Pierwszym prezesem Banku Polskiego SA został Stanisław Karpiński - wybitny ekonomista, bankowiec i minister skarbu. Jako teoretyk i praktyk cieszył się niekwestionowanym autorytetem zarówno w środowisku bankowym, jak i politycznym.
W niedawnych badaniach zasugerowano, że wynagrodzenia poniżej prawnie ustalonej płacy minimalnej są zaskakująco powszechnym zjawiskiem. W niniejszym artykule omówiono tzw. „kradzież płac” w Stanach Zjednoczonych oraz jej wpływ na wzrost wynagrodzeń, który mógłby być udziałem pracowników.
W kwietniu przypada 100. rocznica utworzenia Banku Polskiego SA oraz wprowadzenia złotego do obiegu. Z tej okazji 11 kwietnia odbyła się konferencja „Narodowy Bank Polski – nowy horyzont” poświęcona głównie teraźniejszości i przyszłości.
Najnowsze wydanie „Obserwatora Finansowego” ukazuje nam wizje przyszłości bliskiej i dalekiej. W tym numerze, najlepsi eksperci postarają się odpowiedzieć na kilka kluczowych pytań, dotyczących sztucznej inteligencji i tego jak generatywna AI wpłynie na bankowość, edukację oraz inne dziedziny naszego życia.
Nieefektywność nadzoru prowadzi do występowania nieprawidłowości i nadużyć na rynku funduszy inwestycyjnych w Polsce – taką sensacyjną tezę stawiają autorzy monografii „Nieprawidłowości i nadużycia na rynku funduszy inwestycyjnych”.
Sztuczna inteligencja powoli zmienia sposób działania banków i instytucji finansowych. Pomaga im zredukować ciężar biurokracji, ale także podejmować szybsze decyzje oraz utrzymywać efektywny kontakt z klientami. A będzie jeszcze lepiej. W perspektywie czeka kilkunastoprocentowy wzrost EBITDA.
Budowa Centralnego Portu Komunikacyjnego wzmocniłaby znacznie pozycję Polski w europejskiej gospodarce – stwierdził w rozmowie z „Obserwatorem Finansowym" dr Andreas Wittmer, dyrektor zarządzający Centrum Badań Lotniczych na Uniwersytecie w St. Gallen.
Dywersyfikacja metod płatności, rozumiana jako poszerzanie dostępnej ich gamy, zwiększa wybór płatników i odbiorców płatności, stymuluje konkurencję na rynku i innowacyjność dostawców usług płatniczych, redukuje ryzyko, ponieważ uniezależnia rynek płatności od jednego, potencjalnie dominującego systemu płatności. Podobnie ma się sprawa z formami pieniądza, które się uzupełniają a jednocześnie konkurują i substytuują wzajemnie.
Współczesne problemy prawne Unii Europejskiej, sztuczna inteligencja w bankowości oraz polityka pieniężna były tematami grudniowego zjazdu na podyplomowych studiach MBA organizowanych w ramach drugiej edycji projektu „Akademia NBP”.
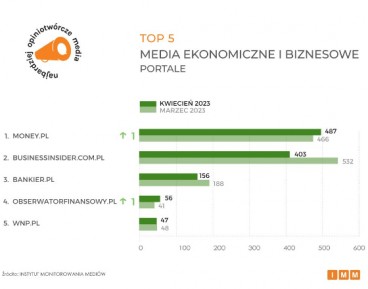
Portal ekonomiczny NBP „Obserwator Finansowy” ponownie znalazł się w czołówce najbardziej opiniotwórczych mediów w kategorii „Media ekonomiczne i biznesowe”, wyprzedzając m.in. „Parkiet”. Wzrost cytowalności treści publikowanych na łamach serwisu wzrósł w kwietniu w odniesieniu do marca 2023 r. o 37 proc.
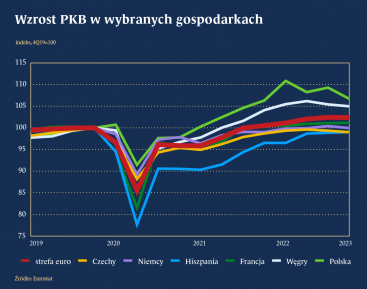
Sytuacja gospodarcza w Polsce na tle innych krajów przedstawia się korzystnie. Warto zauważyć, że w szybkim tempie nadrabiamy dystans dzielący Polskę od poziomu życia w wybranych państwach europejskich. W ciągu ostatnich czterech lat dynamika wzrostu PKB plasowała Polskę powyżej innych krajów europejskich, zarówno strefy euro, w tym Niemiec i Francji, jak i krajów Unii Europejskiej z własną walutą, np. Czech.
Większość polskich przedsiębiorców odczuła skutki wojny w Ukrainie, choć jej wpływ oceniają w zróżnicowany sposób – wynika z badania przeprowadzonego przez Polski Instytut Ekonomiczny.
W styczniu 2020 roku Wielka Brytania formalnie opuściła Unię Europejską. Oczekiwane korzyści z brexitu, poza odzyskaniem suwerenności w zakresie kształtowania prawa i zewnętrznych relacji gospodarczych, jednak się nie zmaterializowały. Widoczny jest natomiast spadek wydajności i konkurencyjności brytyjskiej gospodarki, co wpływa także na kondycję rynku pracy.