Dostosowanie analiz i modelowania makroekonomicznego do szoków ostatnich lat
Kategoria: Trendy gospodarcze„Obyś żył w ciekawych czasach” – ta chińska klątwa przychodzi na myśl przy kolejnych wstrząsach, które spadają na nas w ostatnich latach.

Zaletą tych dodatkowych danych jest możliwość obserwowania cen w wysokiej częstotliwości, a główną wadą – wysoce nieuporządkowany charakter. Są dodatkowym źródłem wiedzy, a umiejętnie wykorzystane mogą wspierać procesy decyzyjne.
Wykorzystanie cen ze sklepów internetowych w badaniach ekonomicznych zyskuje coraz większą popularność. Jedne z bardziej znaczących tego typu analiz są prowadzone w ramach uruchomionego w 2008 r. na MIT projektu Billion Prices Project, który polega na pozyskiwaniu ogromnej ilości danych granularnych o cenach towarów i usług z Internetu (Cavallo i Ribogon, 2016 i cytowania tamże). Zbieranie tego typu danych jest możliwe dzięki szybkiemu przeszukiwaniu stron internetowych sprzedawców detalicznych pod kątem informacji o cenach towarów i usług oraz wszelkich innych cechach tych dóbr za pomocą automatycznej procedury zwanej z angielskiego web scraping.
Szybko okazało się, że pozyskanie tego typu danych wiąże się z wieloma korzyściami. Z punktu widzenia praktyki prowadzenia polityki makroekonomicznej kluczową zaletą tzw. danych skrapowanych (ang. web scraped data) jest możliwość obserwacji i pomiaru pewnych zjawisk (np. cen, popytu, podaży czy opinii) w czasie rzeczywistym. Wraz z rozwojem tych niestandardowych, unikalnych zbiorów danych nastąpił rozkwit literatury ekonomicznej im poświęconej. Nawet zawężając pole zainteresowania wyłącznie do analiz sfery nominalnej, należy wskazać, że w ostatnich latach pojawiło się wiele badań dotyczących pomiaru inflacji, sztywności cen internetowych, segmentacji rynku czy wpływu szoków ekonomicznych, zmian kursów walutowych i podatków na ceny produktów sprzedawanych w sieci (m.in. Lünnemann i Wintr, 2011; Cavallo 2013; Cavallo i Ribogon, 2016; Cavallo, 2017; Gorodnichenko i Talavera, 2017, Cavallo, 2018; Gorodnichenko i in., 2018).
Wysoka częstotliwość obserwacji cen w sklepach internetowych skłoniła badaczy do próby wykorzystania ich do prognozowania inflacji. Dotychczasowy wieloletni konsensus w literaturze wskazuje, że przewidywanie kształtowania się dynamiki cen towarów i usług konsumpcyjnych jest uporczywie trudnym wyzwaniem dla prognostów. Prominentni ekonomiści dowodzą niemal jednogłośnie, że w krótkim okresie proste modele oparte wyłącznie na przeszłych danych o inflacji dostarczają prognoz, które trudno pobić w systematyczny sposób przy wykorzystaniu skomplikowanych metod (m.in. Atkeson i Ohanian, 2001; Stock i Watson, 2007; Faust i Wright, 2013).
Dotychczasowy wieloletni konsensus w literaturze wskazuje, że przewidywanie kształtowania się dynamiki cen towarów i usług konsumpcyjnych jest uporczywie trudnym wyzwaniem dla prognostów.
W tym kontekście ceny ze sklepów internetowych stanowią pewne novum. Skoro można je obserwować w czasie rzeczywistym, to może okazać się, że są one przydatne również do prognozowania inflacji, w szczególności w horyzoncie bieżącym (tzw. nowcast). Taka hipoteza przyświecała Aparicio i Bertolotto (2020), którzy sprawdzili, czy wykorzystanie tego typu danych sprzyja poprawie jakości krótkookresowych prognoz inflacji. Analizując okres od lipca 2008 r. do września 2016 r. dla dziesięciu rozwiniętych gospodarek, autorzy dowiedli, że ceny ze sklepów internetowych stanowią wartościowe źródło danych i zwiększają precyzję prognoz inflacji w krótkim okresie, zwłaszcza gdy cenami z Internetu zasili się proste modele szeregów czasowych.
Rynek detaliczny w Polsce: rozwój e-commerce i nowe wyzwania
W tym artykule analizujemy przydatność cen internetowych w prognozowaniu inflacji cen żywności w Polsce. Nasze badanie motywowane jest tym, że trudno jest bezpośrednio przełożyć część wniosków z literatury dotyczących rozwiniętych gospodarek do specyfiki polskiej gospodarki i rozwijającego się wciąż rynku e-commerce. Po pierwsze, sprawdzamy czy ceny w sklepach internetowych są dobrym przybliżeniem dla oficjalnego wskaźnika inflacji cen żywności i napojów bezalkoholowych. Po drugie, analizujemy ich przydatność w prognozowaniu tego wskaźnika w bieżącym horyzoncie.
W celu odpowiedzi na oba pytania wykorzystujemy ogromną bazę danych internetowych cen żywności i napojów bezalkoholowych, którą zasilamy automatycznie cenami ze stron internetowych największych sprzedawców internetowych w Polsce od 2009 roku. W badaniu wykorzystujemy informację płynącą z niemal 159 milionów cen dla około 650 tysięcy produktów z 8 sklepów internetowych działających w Polsce. Nasze podejście jest metodycznie podobne do analizy Aparicio i Bertolotto (2020), ale uzupełniamy wnioski tych autorów w wielu aspektach. Po pierwsze, podczas gdy wspomniani ekonomiści prognozują jedynie inflację CPI ogółem, my skupiamy się na prognozowaniu inflacji cen żywności i napojów bezalkoholowych oraz wszystkich jej składowych, co pozwala nam na szczegółowe przeanalizowanie jakości naszych prognoz na poziomie zdezagregowanym. Po drugie, swoje badanie opieramy na danych o cenach internetowych obserwowanych na rozwijającym się rynku e-commerce w małej, otwartej gospodarce, podczas gdy wcześniejsze wnioski dotyczyły gospodarek rozwiniętych. Po trzecie, wskazujemy, w jaki sposób jakość prognoz zależy od wolumenu danych i stopnia ich selekcji.
Nasz eksperyment prowadzimy dla bieżącego horyzontu w czasie rzeczywistym, a do konkursu prognostycznego włączyliśmy szereg popularnych modeli szeregów czasowych. Estymacja w rekursywnym oknie obejmuje próbę od grudnia 1999 do grudnia 2016. Jakość prognoz oceniamy w okresie od stycznia 2017 r. do grudnia 2020 r. za pomocą dwóch popularnych statystyk, tj. średniego błędu prognozy (MFE) i pierwiastka z błędu średniokwadratowego prognozy (RMSFE). Metryki te wskazują odpowiednio na obciążenie prognozy (tj. popełnianie systematycznego niedoszacowania bądź przeszacowania) oraz jej precyzję (niezależnie od znaku błędu prognozy). Ponadto porównujemy dokładność naszych prognoz przy wykorzystaniu testu Diebolda i Mariano (1995), który odpowiada na pytanie, czy błędy prognoz z konkurujących modeli są na tyle duże, że stają się rozróżnialne w sensie statystycznym.
Nasze wyniki wskazują, że wykorzystanie cen ze sklepów internetowych prowadzi do dokładniejszych prognoz inflacji cen żywności w Polsce.
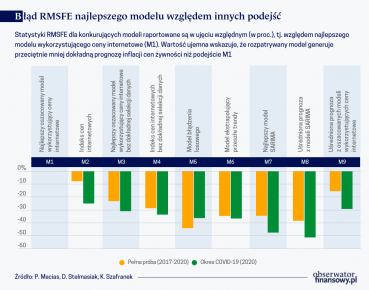
Nasze wyniki wskazują, że wykorzystanie cen ze sklepów internetowych prowadzi do dokładniejszych prognoz inflacji cen żywności w Polsce. Główne wyniki naszego badania podsumowujemy na pierwszym wykresie. Okazuje się, że uwzględnienie informacji o cenach ze sklepów internetowych nawet w nieskomplikowanych modelach szeregów czasowych umożliwia znaczne zwiększenie dokładności prognoz inflacji cen żywności w porównaniu z większością konkurencyjnych podejść. W szczególności, prognozy z naszego rekursywnie optymalizowanego modelu (M1) są znacznie dokładniejsze niż prognozy z modeli błądzenia losowego czy modelu SARIMA (M5-M7). W tych przypadkach dokładność prognozy mierzona statystyką RMSFE (tj. pierwiastka z błędu średniokwadratowego) rośnie o ok. 34-44 proc.
Należy podkreślić, że różnica ta jest statystycznie istotna na poziomie 1 proc. według wskazania testu Diebolda i Mariano (1995), co oznacza, że korzyść z uwzględniania dodatkowych informacji o cenach jest naprawdę wyraźna. Jednocześnie, prognozy te charakteryzują się bardzo niskim obciążeniem – przeciętnie nie odchylają się systematycznie w żadną ze stron, co ilustruje drugi wykres. Innymi słowy, nie następuje zarówno systematyczne przeszacowanie, jak i niedoszacowanie inflacji cen żywności w horyzoncie prognozy.
Ciekawym wnioskiem dla prognostów jest również to, że przybliżanie inflacji cen żywności samym indeksem cen online (M2) zapewnia obniżenie błędu RMSFE w porównaniu z prognozami z tradycyjnych modeli, nawet o 29-39 proc. Jest to niezwykle istotny wynik dla praktyków prognozowania w bankach centralnych. Ilustruje on, że już po kilku miesiącach zbierania danych można z powodzeniem wykorzystać ceny ze sklepów internetowych do eksperckiej korekty prognozy na bieżący miesiąc (w przypadku krótkich szeregów czasowych szacowanie modeli szeregów czasowych jest zazwyczaj niemal niemożliwe).
W przypadku uśredniania prognoz nasze wyniki stoją w kontrze do konsensusu ustalonego w literaturze. Wskazujemy, że uśrednienie prognoz z wszystkich rozpatrywanych modeli o równych wagach nie daje przeciętnie najlepszych wyników i może prowadzić do większego obciążenia prognoz. Zastrzegamy przy tym, że wynik ten jest pochodną bardzo rygorystycznego wyboru najlepszego modelu oddzielnie dla każdej składowej koszyka produktów.
Praktycy mogą być zainteresowani, jakiego rodzaju wysiłek należy podjąć, by lepiej prognozować inflację. W tym celu postanowiliśmy sprawdzić, czy nasz błąd prognozy zależy od ilości uwzględnianych przez nas danych ze sklepów internetowych. W tym eksperymencie przeanalizowaliśmy zatem dokładność prognostyczną indeksu cen internetowych na wszystkich możliwych podpróbach sklepów internetowych, które śledzimy. Okazuje się, że przeciętnie im większa próba (im więcej sklepów i w związku z tym cen internetowych w naszej bazie), tym niższy błąd prognozy otrzymujemy (ostatni wykres). Jednakże, wraz ze zwiększaniem liczby sklepów w podpróbie krańcowy błąd prognozy spada coraz wolniej.
Okazuje się, że przeciętnie im większa próba (im więcej sklepów i w związku z tym cen internetowych w naszej bazie), tym niższy błąd prognozy otrzymujemy.
Wynikają z tego dwa wnioski. Po pierwsze, wzrost liczby śledzonych sklepów internetowych można traktować jako swoistą dywersyfikację ryzyka obserwowania w swojej próbie nietypowych zmian cen. Po drugie, błąd jest nieodłączną cechą wszystkich prognoz, toteż uwzględnienie kolejnych milionów punktów danych nie doprowadzi do jego całkowitej eliminacji.
Liczba wykorzystanych rekordów danych jest ważna, ale równie ważna jest ich jakość. W obliczu generowanych przez Internet ogromnych ilości nieuporządkowanych danych powstaje dylemat, czy wszystkie te dane są jednakowo ważne i przydatne dla ekonomistów? Na podstawie naszych wyników okazuje się, że zdecydowanie warto selekcjonować dane. Wskazujemy, że zastosowanie precyzyjnej klasyfikacji produktów oraz odpowiednie ich ważenie ma ogromne znaczenie dla jakości naszych prognoz. Nasze eksperymenty pokazują, że nadzorowanie procesu klasyfikacji produktów do odpowiednich grup produktowych przez człowieka jest kluczem do sukcesu. Taka dokładność klasyfikacji jest niezbędna, a wykorzystanie uproszczonego przyporządkowania produktów obarczonego błędem (np. opartego na uproszczonych słownikach) powoduje wzrost błędu prognozy o 30-40 proc.
Internet zwiększa konkurencję i ogranicza możliwość wzrostu cen
Na koniec sprawdzamy, czy wykorzystanie niestandardowych źródeł danych jest przydatne w wysoce nietypowych okresach. W tym celu analizujemy jakość prognoz po wybuchu globalnej pandemii COVID-19. Okazuje się, że ceny ze sklepów internetowych stanowiły cenne źródło informacji. Nasze analizy wskazały, że precyzja modelu wzrosła w porównaniu z precyzją tradycyjnych modeli w 2020 r. W szczególności, zauważyliśmy, że prognozy z tradycyjnego modelu, którego dynamika wynika w dużej mierze z uwzględnienia pewnego sezonowego (tj. powtarzalnego) wzorca, okazały się wysoce nietrafne wskutek bardzo nietypowych zmian cen. W efekcie, zarówno obciążenie tego modelu, jak i jego precyzja istotnie wzrosły w tej krótkiej próbie. Z kolei w przypadku naszego najlepszego modelu z cenami z Internetu nie zaobserwowaliśmy istotnej zmiany statystyk jakości prognoz. W efekcie, w ujęciu relatywnym jakość prognoz z tego modelu wzrosła względem prognoz z konkurencyjnych modeli i była ona prawie dwukrotnie wyższa niż modelu uwzględniającego wzorzec sezonowy. Ze względu na bardzo krótką próbę tym razem nie ocenialiśmy statystycznej istotności tej różnicy.
Wyniki naszych analiz wskazują, że ceny internetowe stanowią cenne źródło informacji o procesach inflacyjnych, a ich zbieranie i umiejętne przetwarzanie umożliwia lepsze prognozowanie inflacji. Na podstawie naszych analiz należy wskazać, że wykorzystanie prostych modeli uwzględniających informacje o cenach internetowych prowadzi do znacznej poprawy dokładności prognoz. Ważne jest jednak to, by wykorzystywać dane z możliwie wielu źródeł i systematycznie dbać o ich jakość.
Opinie wyrażone w tym artykule są opiniami autorów i nie odzwierciedlają oficjalnego stanowiska Narodowego Banku Polskiego. Artykuł ten został opracowany na podstawie badania naukowego przyjętego do publikacji w wiodącym czasopiśmie poświęconym tematyce prognostycznej International Journal of Forecasting.
Paweł Macias– Doradca w Wydziale Inflacji i Cen, Departament Analiz i Badań Ekonomicznych, Narodowy Bank Polski.
Damian Stelmasiak – Główny specjalista ds. analiz Big Data, Departament Statystyki, Narodowy Bank Polski.
Karol Szafranek – Doradca ekonomiczny kierujący Wydziałem Inflacji i Cen, Departament Analiz i Badań Ekonomicznych, Narodowy Bank Polski.

















W styczniu 2020 roku Wielka Brytania formalnie opuściła Unię Europejską. Oczekiwane korzyści z brexitu, poza odzyskaniem suwerenności w zakresie kształtowania prawa i zewnętrznych relacji gospodarczych, jednak się nie zmaterializowały. Widoczny jest natomiast spadek wydajności i konkurencyjności brytyjskiej gospodarki, co wpływa także na kondycję rynku pracy.
